Обзор Архитектуры
Это веб-версия нашей научной статьи VLDB 2024. Мы также опубликовали блог о её предыстории и пути, и рекомендуем посмотреть презентацию VLDB 2024 от CTO и создателя ClickHouse, Алексея Миловидова:
АННОТАЦИЯ
За последние несколько десятилетий объем хранимых и анализируемых данных увеличился в геометрической прогрессии. Бизнесы в различных отраслях и секторах начали полагаться на эти данные для улучшения продуктов, оценки эффективности и принятия критически важных бизнес-решений. Однако с ростом объемов данных, которые становятся масштабируемыми в интернет-пространстве, бизнесам необходимо управлять историческими и новыми данными экономически и масштабируемо, одновременно анализируя их с использованием большого количества параллельных запросов и с ожиданием реального времени задержек (например, менее одной секунды, в зависимости от случая использования).
В этой статье представлен обзор ClickHouse, популярной открытой OLAP базы данных, разработанной для высокопроизводительной аналитики над данными в масштабе петабайтов с высоким уровнем загрузки. Его слой хранения объединяет формат данных на основе традиционных слияний, структурированных как деревья LSM, с новыми техниками непрерывной трансформации (например, агрегации, архивирования) исторических данных в фоновом режиме. Запросы пишутся на удобном диалекте SQL и обрабатываются современным векторизированным движком выполнения запросов с опциональной компиляцией кода. ClickHouse активно использует техники обрезки для избегания обработки нерелевантных данных в запросах. Другие системы управления данными могут быть интегрированы на уровне табличной функции, ^^движка таблиц^^ или движка базы данных. Реальные бенчмарки демонстрируют, что ClickHouse входит в число самых быстрых аналитических баз данных на рынке.
1 ВВЕДЕНИЕ
В данной статье описан ClickHouse, столбцовая OLAP база данных, предназначенная для высокопроизводительных аналитических запросов к таблицам с триллионами строк и сотнями колонок. ClickHouse был начат в 2009 году как оператор фильтрации и агрегации для данных журнальных файлов веб-масштабов и был открыт в 2016 году. Рисунок 1 иллюстрирует, когда основные функции, описанные в этой статье, были введены в ClickHouse.
ClickHouse разработан для решения пяти ключевых задач современного управления аналитическими данными:
-
Огромные наборы данных с высокой скоростью загрузки. Многие приложения, зависящие от данных, в таких отраслях, как веб-аналитика, финансы и электронная коммерция, характеризуются огромными и постоянно растущими объемами данных. Для обработки больших наборов данных аналитические базы данных должны не только обеспечивать эффективные стратегии индексирования и сжатия, но также позволять распределение данных между несколькими узлами (масштабирование) из-за ряда ограничений серверов, которые могут справляться только с несколькими десятками терабайтов хранения. Кроме того, недавние данные часто более актуальны для реальных выводов, чем исторические данные. В результате аналитические базы данных должны иметь возможность загружать новые данные на постоянной высокой скорости или в пакетах, а также непрерывно "понижать приоритет" (например, агрегировать, архивировать) исторические данные без замедления параллельных отчетных запросов.
-
Множество одновременных запросов с ожиданием низких задержек. Запросы можно в общем случае разделить на разовые (например, для исследовательского анализа данных) или повторяющиеся (например, периодические запросы для панелей мониторинга). Чем интерактивнее случай использования, тем ниже ожидаются задержки запросов, что приводит к челленджам в оптимизации запросов и их выполнении. Повторяющиеся запросы дополнительно предоставляют возможность адаптировать физическую компоновку базы данных под нагрузку. В результате базы данных должны предлагать техники обрезки, которые позволяют оптимизировать частые запросы. В зависимости от приоритета запроса базы данных должны обеспечивать равный или приоритетный доступ к общим системным ресурсам, таким как CPU, память, диск и ввод-вывод сети, даже если множество запросов выполняются одновременно.
-
Разнообразные ландшафты хранилищ данных, местоположений и форматов хранения. Для интеграции с существующими архитектурами данных современные аналитические базы данных должны продемонстрировать высокую степень открытости для чтения и записи внешних данных в любой системе, местоположении или формате.
-
Удобный язык запросов с поддержкой производственной индикации. Реальное использование OLAP баз данных предъявляет дополнительные "мягкие" требования. Например, вместо узкоспециализированного языка программирования пользователи часто предпочитают взаимодействовать с базами данных на выразительном SQL диалекте с вложенными типами данных и широким набором обычных, агрегатных и оконных функций. Аналитические базы данных также должны предоставлять сложные инструменты для анализа производительности системы или отдельных запросов.
-
Устойчивость уровня промышленности и универсальное развертывание. Поскольку обычное оборудование ненадежно, базы данных должны предоставлять репликацию данных для устойчивости к сбоям узлов. Также базы данных должны работать на любом оборудовании, от старых ноутбуков до мощных серверов. Наконец, чтобы избежать накладных расходов на сбор мусора в программах на базе JVM и обеспечить производительность на уровне "bare-metal" (например, SIMD), базы данных идеальным образом разворачиваются как нативные двоичные файлы для целевой платформы.

Рисунок 1: Хронология ClickHouse.
2 АРХИТЕКТУРА
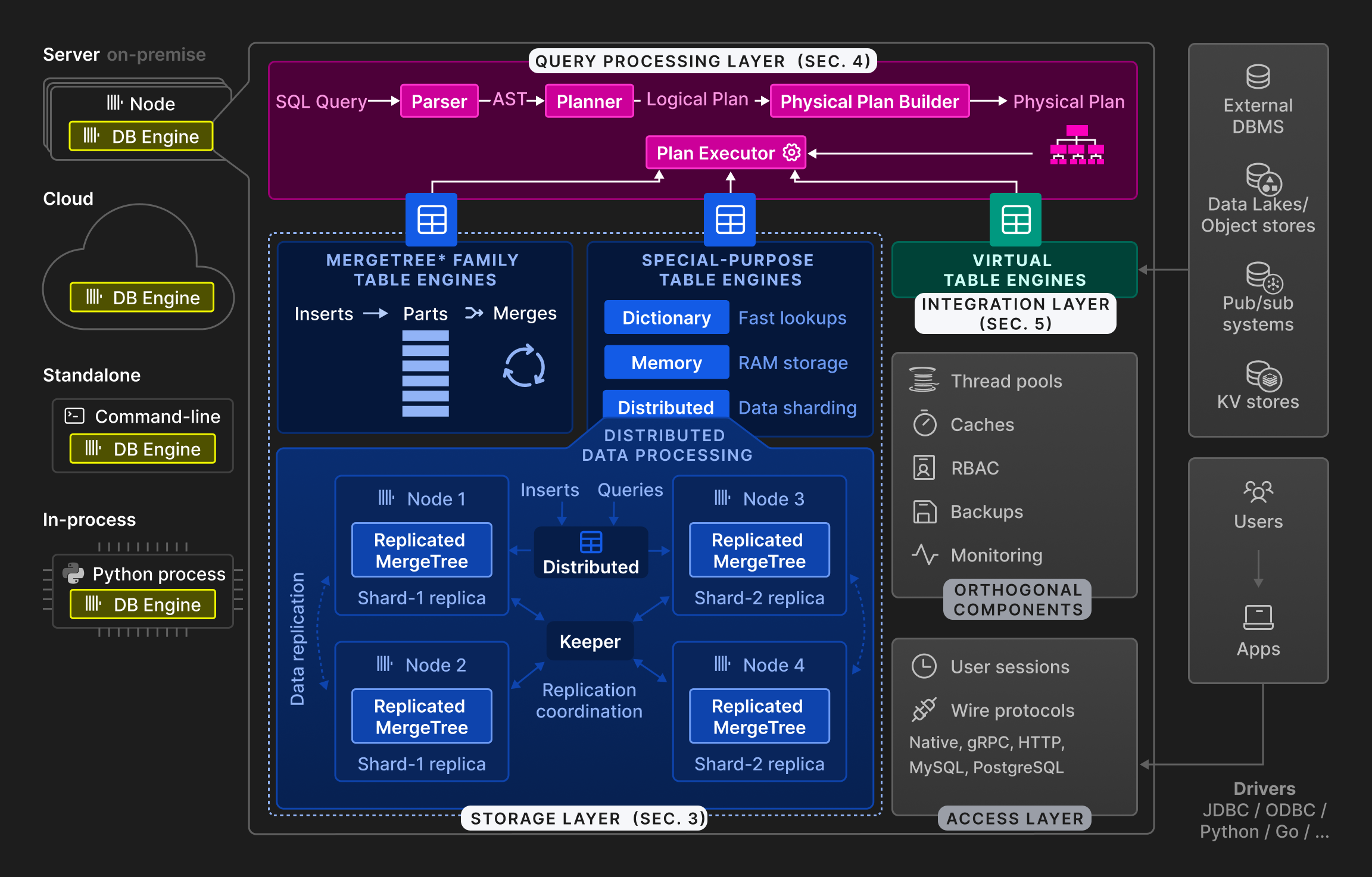
Рисунок 2: Архитектура ClickHouse на высоком уровне.
Как показано на Рисунке 2, движок ClickHouse разделен на три основные слоя: слой обработки запросов (описан в Разделе 4), слой хранения (Раздел 3) и интеграционный слой (Раздел 5). Кроме этого, имеется слой доступа, который управляет пользовательскими сессиями и коммуникацией с приложениями через различные протоколы. Есть ортогональные компоненты для потоков, кэширования, контроля доступа на основе ролей, резервного копирования и непрерывного мониторинга. ClickHouse написан на C++ как единый статически скомпилированный бинарный файл без зависимостей.
Обработка запросов следует традиционной парадигме парсинга входящих запросов, построения и оптимизации логических и физических планов запросов и их выполнения. ClickHouse использует векторизированную модель выполнения, аналогичную MonetDB/X100 [11], в сочетании с оппортунистической компиляцией кода [53]. Запросы могут быть написаны на богатом SQL диалекте, PRQL [76], или KQL от Kusto [50].
Слой хранения состоит из различных движков таблиц, которые инкапсулируют формат и расположение данных таблицы. Движки таблиц делятся на три категории: первая категория — это ^^MergeTree^^* семейство движков таблиц, которые представляют собой основной формат сохранения в ClickHouse. Основываясь на идее деревьев LSM [60], таблицы разбиваются на горизонтальные, отсортированные ^^части^^, которые непрерывно объединяются фоновым процессом. Индивидуальные ^^MergeTree^^* двигатели таблиц различаются по тому, как именно слияние объединяет строки из своих входных ^^частей^^. Например, строки могут быть агрегированы или заменены, если устарели.
Вторая категория — это специализированные движки таблиц, которые используются для ускорения или распределения выполнения запросов. В эту категорию входят таблицы в оперативной памяти, основанные на ключ-значение, называемые словарями. Словарь кэширует результат запроса, периодически выполняемого против внутреннего или внешнего источника данных. Это значительно сокращает задержки доступа в сценариях, где можно допустить некоторую степень устаревания данных. Другие примеры специализированных движков таблиц включают чистый движок в памяти, используемый для временных таблиц, и ^^Distributed table^^ движок для прозрачного шардирования данных (см. ниже).
Третья категория движков таблиц — это виртуальные движки таблиц для двунаправленного обмена данными с внешними системами, такими как реляционные базы данных (например, PostgreSQL, MySQL), системы публикации/подписки (например, Kafka, RabbitMQ [24]), или хранилища на основе ключ-значение (например, Redis). Виртуальные движки также могут взаимодействовать с ДатаЛэйками (например, Iceberg, DeltaLake, Hudi [36]) или файлами в объектном хранилище (например, AWS S3, Google GCP).
ClickHouse поддерживает шардирование и репликацию таблиц на нескольких ^^узлах кластера^^ для масштабируемости и доступности. Шардирование разбивает таблицу на набор шардов таблицы в соответствии с выражением шардирования. Индивидуальные шарды являются взаимозависимыми таблицами и обычно располагаются на разных узлах. Клиенты могут читать и писать в шарды напрямую, т.е. относиться к ним как к отдельным таблицам, или использовать специализированный ^^Distributed table^^ движок, который предоставляет глобальный обзор всех шардов таблицы. Основная цель шардирования — обрабатывать наборы данных, превышающие емкость отдельных узлов (обычно несколько десятков терабайтов данных). Другими словами, шардирование может использоваться для распределения нагрузки на чтение-запись для таблицы по нескольким узлам, т.е. для балансировки нагрузки. Вдобавок ^^шард^^ может быть реплицирован по нескольким узлам для устойчивости к сбоям узлов. Для этого у каждого движка таблицы MergeTree* есть соответствующий движок ReplicatedMergeTree*, который использует многомастеровую схему координации, основанную на консенсусе Raft [59] (реализованном Keeper, заменой Apache Zookeeper, написанной на C++), чтобы гарантировать, что каждый ^^шард^^ имеет в любое время настраиваемое количество реплик. Раздел 3.6 подробно обсуждает механизм репликации. В качестве примера, Рисунок 2 показывает таблицу с двумя шардми, каждая из которых реплицирована на два узла.
Наконец, движок базы данных ClickHouse может работать в режимах локального развертывания, облака, автономного или в процессе. В режиме локального развертывания пользователи настраивают ClickHouse локально как один сервер или многосерверный ^^кластер^^ с шардированием и/или репликацией. Клиенты взаимодействуют с базой данных через нативный, двоичный протокол MySQL, протокол PostgreSQL или через HTTP REST API. Режим облака представлен ClickHouse Cloud, полностью управляемым и автошкалируемым предложением DBaaS. Хотя эта статья сосредоточена на режиме локального развертывания, мы планируем описать архитектуру ClickHouse Cloud в последующих публикациях. Автономный режим превращает ClickHouse в утилиту командной строки для анализа и преобразования файлов, делая его SQL-альтернативой для Unix инструментов, таких как cat и grep. Хотя это не требует предварительной конфигурации, автономный режим ограничен одним сервером. В последнее время был разработан встроенный режим, называемый chDB [15], для интерактивного анализа данных, таких как Jupyter notebooks [37] с фреймами данных Pandas [61]. Вдохновленный DuckDB [67], chDB встраивает ClickHouse как высокопроизводительный OLAP движок в хост-процесс. В отличие от других режимов, это позволяет эффективно передавать исходные и итоговые данные между движком базы данных и приложением без копирования, так как они работают в одном адресном пространстве.
3 СЛОЙ ХРАНЕНИЯ
В этом разделе обсуждаются ^^MergeTree^^* движки таблиц как родной формат хранения ClickHouse. Мы описываем их представление на диске и обсуждаем три техники обрезки данных в ClickHouse. После этого мы представляем стратегии слияния, которые непрерывно трансформируют данные без влияния на одновременные вставки. Наконец, мы объясняем, как реализованы обновления и удаления, а также дедупликация данных, репликация данных и соответствие стандартам ACID.
3.1 Формат на диске
Каждая таблица в ^^MergeTree^^* ^^движке таблиц^^ организована как коллекция неизменяемых ^^частей^^ таблицы. ^^Часть^^ создается каждый раз, когда набор строк вставляется в таблицу. ^^Части^^ содержат все метаданные, необходимые для интерпретации их содержимого без дополнительных обращений к центральному каталогу. Чтобы поддерживать низким количество ^^частей^^ на таблицу, фоновая задача слияния периодически объединяет несколько мелких ^^частей^^ в одну большую часть, пока не будет достигнут настраиваемый размер части (по умолчанию 150 ГБ). Поскольку ^^части^^ отсортированы по колонкам ^^первичного ключа^^ таблицы (см. Раздел 3.2), для слияния используется эффективная k-ступенчатая сортировка [40]. Исходные ^^части^^ помечаются как неактивные и в конечном итоге удаляются, как только их счетчик ссылок опускается до нуля, т.е. из них больше нет дальнейших чтений запросов.
Строки могут быть вставлены в двух режимах: в режиме синхронной вставки каждое предложение INSERT создает новую часть и добавляет ее в таблицу. Чтобы минимизировать накладные расходы на слияния, клиентам базы данных рекомендуется вставлять кортежи оптом, например, по 20,000 строк за раз. Однако задержки, вызванные пакетной вставкой на стороне клиента, часто недопустимы, если данные должны быть проанализированы в реальном времени. Например, случаи наблюдаемости часто требуют от нескольких тысяч агентов мониторинга непрерывной отправки небольших объемов событий и метрик. Такие сценарии могут использовать режим асинхронной вставки, в котором ClickHouse буферизует строки от нескольких входящих INSERT в одну таблицу и создает новую часть только после того, как размер буфера превышает настраиваемый порог или истекает тайм-аут.
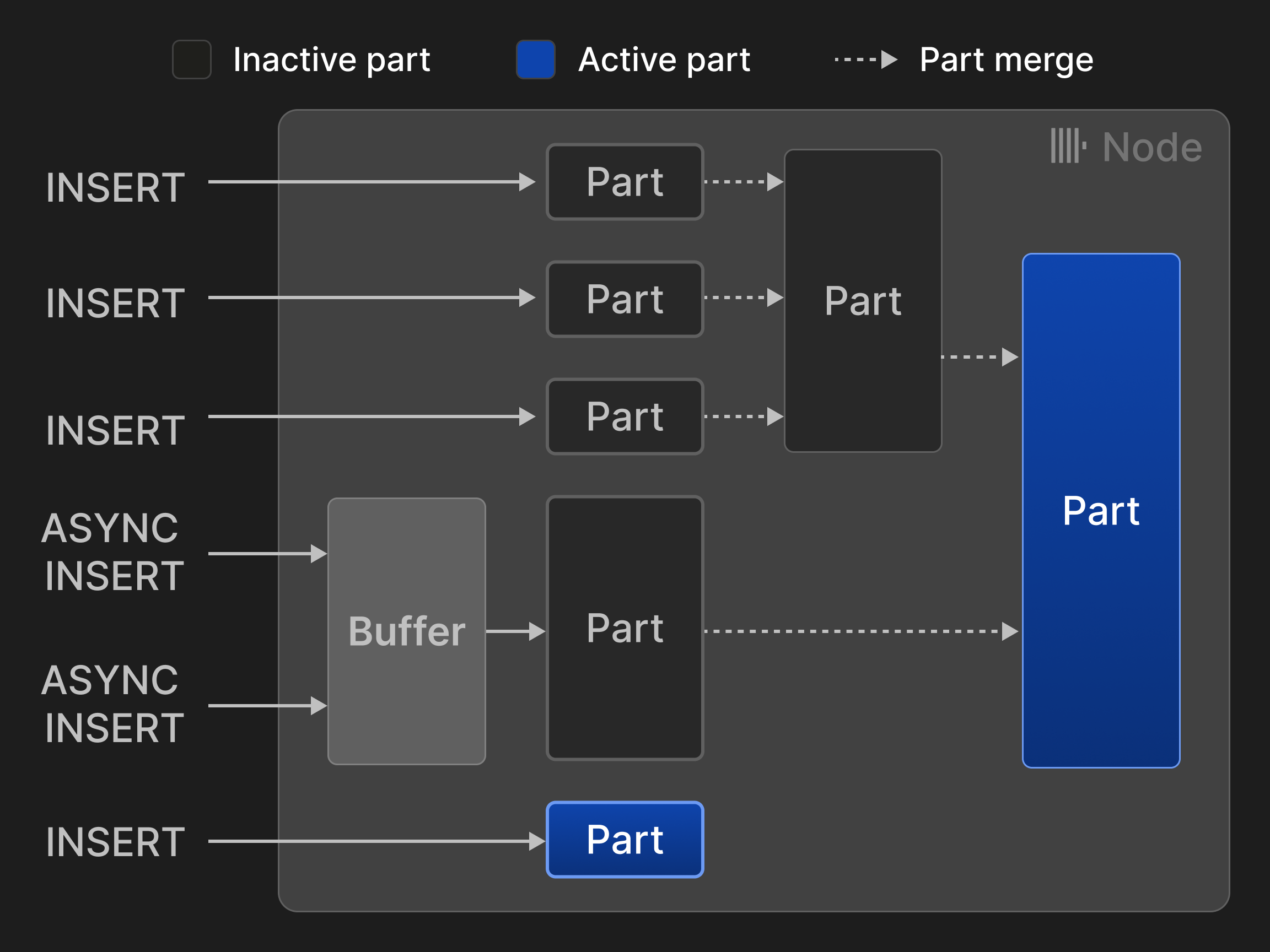
Рисунок 3: Вставки и слияния для таблиц движка ^^MergeTree^^*.
Рисунок 3 иллюстрирует четыре синхронные и две асинхронные вставки в таблицу движка ^^MergeTree^^*. Два слияния сократили количество активных ^^частей^^ с изначальных пяти до двух.
В сравнении с деревьями LSM [58] и их реализацией в различных базах данных [13, 26, 56], ClickHouse рассматривает все ^^части^^ как равные, а не располагает их в иерархию. В результате слияния больше не ограничиваются ^^частями^^ в одном уровне. Поскольку это также предотвращает неявный хронологический порядок ^^частей^^, необходимы альтернативные механизмы для обновлений и удалений, которые не основаны на маркерах удаления (см. Раздел 3.4). ClickHouse записывает вставки непосредственно на диск, в то время как другие хранилища на базе деревьев LSM обычно используют ведущее журналирование (см. Раздел 3.7).
Часть соответствует каталогу на диске, содержащему один файл на каждую колонку. В качестве оптимизации колонки маленькой части (меньше 10 МБ по умолчанию) хранятся последовательно в одном файле, чтобы повысить пространственную локальность для чтений и записей. Строки части дополнительно логически делятся на группы по 8192 записи, называемые гранулами. ^^Гранула^^ представляет собой наименьшую неделимую единицу данных, обрабатываемую операторами поиска и индексного поиска в ClickHouse. Чтения и записи на диске не выполняются на уровне ^^гранулы^^, а на уровне блоков, которые объединяют несколько соседних гранул в пределах одной колонки. Новые блоки формируются на основе настраиваемого размера в байтах для каждого ^^блока^^ (по умолчанию 1 МБ), т.е. количество гранул в ^^блоке^^ переменное и зависит от типа данных и распределения колонки. Блоки дополнительно сжимаются для уменьшения их размера и затрат на ввод-вывод. По умолчанию ClickHouse использует LZ4 [75] как алгоритм сжатия общего назначения, но пользователи также могут указывать специализированные кодеки, такие как Gorilla [63] или FPC [12] для данных с плавающей точкой. Алгоритмы сжатия также могут быть объединены. Например, можно сначала уменьшить логическую избыточность числовых значений, используя дельта-кодирование [23], затем выполнить тяжелое сжатие и, наконец, зашифровать данные с использованием кодека AES. Блоки распаковываются по мере загрузки с диска в память. Чтобы обеспечить быстрый случайный доступ к отдельным гранулам, несмотря на сжатие, ClickHouse дополнительно хранит для каждой колонки отображение, которое связывает каждый ^^идентификатор гранулы^^ с смещением его содержащего сжатого ^^блока^^ в файле колонки и смещением ^^гранулы^^ в несжатом ^^блоке^^.
Колонки также могут быть закодированы как ^^словарные^^ [2, 77, 81] или сделаны принимающими NULL с использованием двух специальных оберток типов данных: LowCardinality(T) заменяет оригинальные значения колонок на целочисленные идентификаторы и тем самым значительно сокращает накладные расходы на хранение для данных с небольшим количеством уникальных значений. Nullable(T) добавляет внутренний битмап к колонке T, который указывает, являются ли значения колонок NULL или нет.
Наконец, таблицы могут быть разбиты на диапазонные, хешированные или круговые партиции с использованием произвольных выражений партиционирования. Чтобы включить обрезку партиций, ClickHouse дополнительно хранит минимальные и максимальные значения выражения партиционирования для каждой партиции. Пользователи могут по желанию создавать более сложную статистику колонок (например, HyperLogLog [30] или t-digest [28]), которые также предоставляют оценки кардинальности.
3.2 Обрезка данных
В большинстве случаев сканирование петабайтов данных только для ответа на один запрос слишком медленно и дорого. ClickHouse поддерживает три техники обрезки данных, которые позволяют пропускать большинство строк во время поиска и, таким образом, значительно ускорять запросы.
Во-первых, пользователи могут определять индекс ^^первичного ключа^^ для таблицы. Колонки ^^первичного ключа^^ определяют порядок сортировки строк внутри каждой части, т.е. индекс локально сгруппирован. ClickHouse дополнительно хранит для каждой части отображение от значений колонок ^^первичного ключа^^ первых строк каждой ^^гранулы^^ до идентификатора ^^гранулы^^, т.е. индекс разрежен [31]. Получившаяся структура данных обычно достаточно мала, чтобы оставаться полностью в памяти, например, всего 1000 записей требуется для индексирования 8.1 миллиона строк. Основная цель ^^первичного ключа^^ заключается в оценке условий равенства и диапазона для часто фильтруемых колонок с использованием двоичного поиска вместо последовательного сканирования (раздел 4.4). Локальная сортировка также может быть использована для слияния частей и оптимизации запросов, например, агрегации на основе сортировки, или для исключения операторов сортировки из физического плана выполнения, когда колонки ^^первичного ключа^^ формируют префикс сортировочных колонок.
Рисунок 4 показывает индекс ^^первичного ключа^^ на колонке EventTime для таблицы со статистикой показов страницы. Гранулы, которые соответствуют диапазону в запросе, могут быть найдены с использованием двоичного поиска по индексу ^^первичного ключа^^, а не сканируя EventTime последовательно.

Рисунок 4: Оценка фильтров с использованием индекса ^^первичного ключа^^.
Во-вторых, пользователи могут создавать проекции таблиц, т.е. альтернативные версии таблицы, которые содержат те же строки, отсортированные по другому ^^первичному ключу^^ [71]. Проекции позволяют ускорять запросы, которые фильтруют по колонкам, отличным от ^^первичного ключа^^ главной таблицы, ценой увеличенных накладных расходов на вставку, слияния и потребление пространства. По умолчанию проекции заполняются лажно только из ^^частей^^, вновь вставленных в главную таблицу, но не из существующих ^^частей^^, если пользователь не материализует ^^проекцию^^ полностью. Оптимизатор запросов выбирает между чтением из главной таблицы или ^^проекции^^ в зависимости от оценок затрат ввода-вывода. Если для части не существует ^^проекции^^, выполнение запроса возвращается к соответствующей части главной таблицы.
В-третьих, индексы пропуска предоставляют легковесную альтернативу проекциям. Идея индексов пропуска состоит в том, чтобы хранить небольшие объемы метаданных на уровне нескольких последовательных гранул, что позволяет избежать сканирования нерелевантных строк. Индексы пропуска могут быть созданы для произвольных выражений индексов и с заданной парциальностью, т.е. количеством гранул в блоке ^^индекса пропуска^^. Доступные типы ^^индексов пропуска^^ включают: 1. Минимально-максимальные индексы [51], хранящие минимальные и максимальные значения выражения индекса для каждого ^^блока^^ индекса. Этот тип индекса хорошо работает для локально сгруппированных данных с небольшими абсолютными диапазонами, например, слабо отсортированные данные. 2. Индексы множества, хранящие настраиваемое количество уникальных значений ^^блока^^ индекса. Эти индексы лучше всего использовать с данными с малой локальной кардинальностью, т.е. "сгруппированными" значениями. 3. Индексы фильтра Блума [9] строятся для значений строк, токенов или n-грамм с заданной вероятностью ложноположительных срабатываний. Эти индексы поддерживают текстовый поиск [73], но в отличие от минимально-максимальных и индексов множества, они не могут быть использованы для диапазонных или отрицательных условий.
3.3 Трансформация данных во время слияния
Сценарии бизнес-аналитики и наблюдаемости часто требуют обработки данных, генерируемых с постоянно высокой скоростью или порциями. Кроме того, недавно сгенерированные данные, как правило, более актуальны для значимых выводов в реальном времени, чем исторические данные. Такие сценарии требуют от баз данных поддерживать высокие уровни загрузки данных, одновременно непрерывно уменьшая объем исторических данных с помощью техник, таких как агрегация или старение данных. ClickHouse позволяет непрерывно и постепенно трансформировать существующие данные с использованием различных стратегий слияния. Трансформация данных во время слияния не компрометирует производительность операторов INSERT, но она не может гарантировать, что таблицы никогда не содержат нежелательных (например, устаревших или неагрегированных) значений. Если необходимо, все трансформации во время слияния могут быть применены в момент выполнения запроса, указав ключевое слово FINAL в операторах SELECT.
Заменяющие слияния сохраняют только последнюю вставленную версию кортежа на основе временной метки создания его содержащей части, старые версии удаляются. Кортежи считаются эквивалентными, если они имеют одинаковые значения колонок ^^первичного ключа^^. Для явного контроля того, какой кортеж сохраняется, также возможно указать специальный столбец версии для сравнения. Заменяющие слияния часто используются как механизм обновления во время слияния (обычно в сценариях с частыми обновлениями) или как аль ternативa к дедупликации данных во время вставки (раздел 3.5).
Агрегационные слияния объединяют строки с равными значениями колонок ^^первичного ключа^^ в одну агрегированную строку. Некакие колонки ^^первичного ключа^^ должны находиться в частичном состоянии агрегации, которое хранит итоговые значения. Два частичных состояния агрегации, например, сумма и счетчик для avg(), объединяются в новое частичное состояние агрегации. Агрегационные слияния обычно используемые в материализованных представлениях, а не в обычных таблицах. Материализованные представления заполняются на основе трансформационного запроса против исходной таблицы. В отличие от других баз данных, ClickHouse не обновляет материализованные представления периодически с полным содержимым исходной таблицы. Вместо этого материализованные представления обновляются постепенно с результатами трансформационного запроса, когда новая часть вставляется в исходную таблицу.
Рисунок 5 показывает ^^материализованное представление^^, определенное для таблицы со статистикой показов страницы. Для новых ^^частей^^, вставленных в исходную таблицу, трансформационный запрос вычисляет максимальные и средние задержки, сгруппированные по регионам, и вставляет результат в ^^материализованное представление^^. Агрегационные функции avg() и max() с расширением -State возвращают частичные состояния агрегации вместо действительных результатов. Агрегационное слияние, определенное для ^^материализованного представления^^, непрерывно комбинирует частичные состояния агрегации в различных ^^частях^^. Чтобы получить конечный результат, пользователи консолидируют частичные состояния агрегации в ^^материализованном представлении^^ с помощью avg() и max() с -Merge расширением.
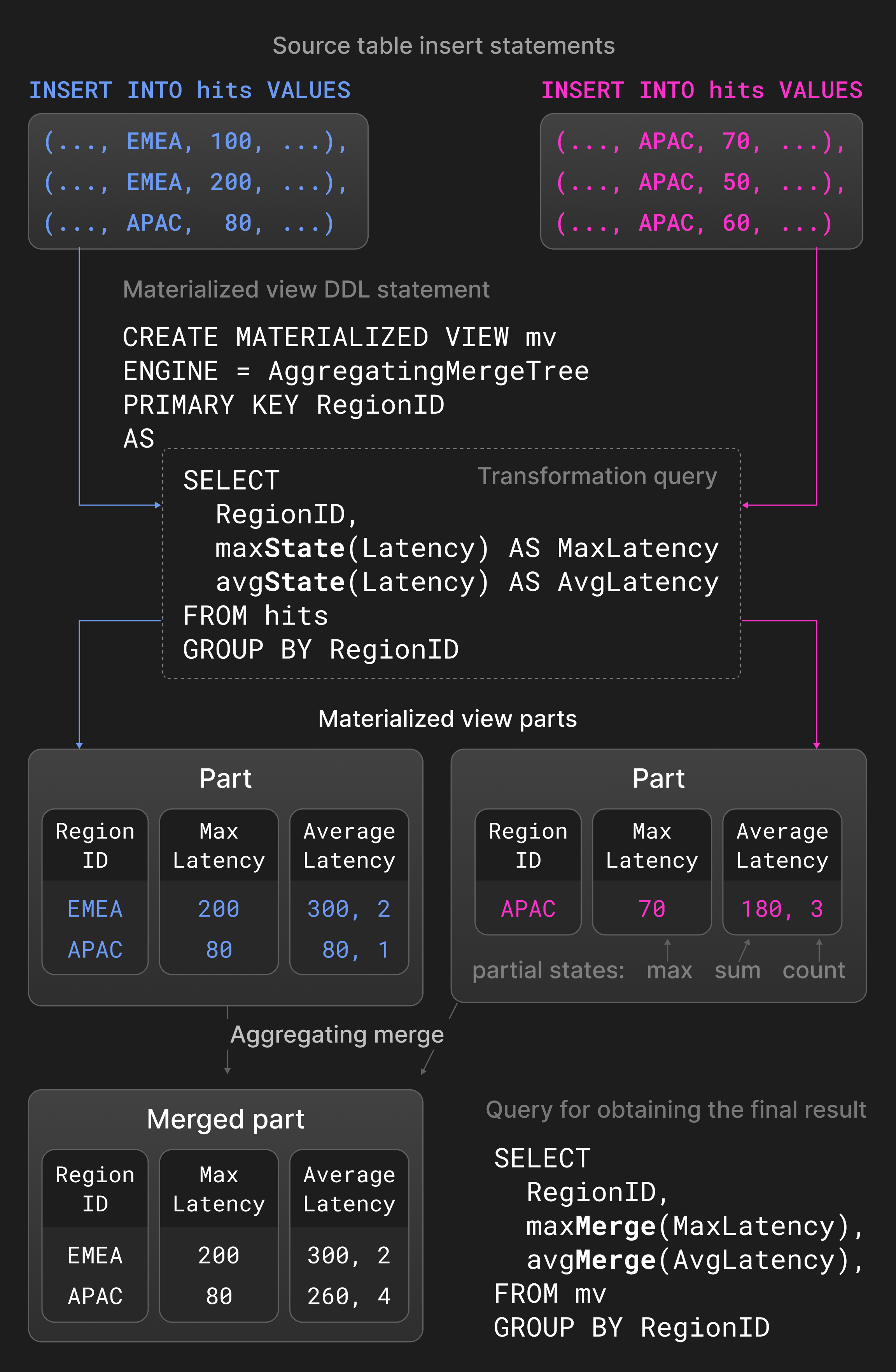
Рисунок 5: Агрегационные слияния в материализованных представлениях.
^^TTL^^ (время жизни) слияния обеспечивают старение исторических данных. В отличие от удаления и агрегационных слияний, ^^TTL^^ слияния обрабатывают только одну часть за раз. ^^TTL^^ слияния определяются в терминах правил с триггерами и действиями. Триггер — это выражение, вычисляющее временную метку для каждой строки, которая затем сравнивается со временем выполнения ^^TTL^^ слияния. Хотя это позволяет пользователям контролировать действия на уровне строки, мы сочли достаточным проверить, удовлетворяют ли все строки данному условию и выполнить действие на всей части. Возможные действия включают 1. перемещение части на другое устройство (например, более дешевое и медленное хранилище), 2. повторное сжатие части (например, с использованием более тяжелого кодека), 3. удаление части и 4. сводка, т.е. агрегация строк с использованием ключа группировки и агрегатных функций.
В качестве примера рассмотрим определение таблицы журналов в Списке 1. ClickHouse переместит ^^части^^ с временными метками колонок старше одной недели в медленное, но дешевое S3 объектное хранилище.
Список 1: Перемещение части в объектное хранилище после одной недели.
3.4 Обновления и удаления
Дизайн ^^MergeTree^^* движков таблиц ориентирован на нагрузки только на добавление, однако для некоторых сценариев требуется время от времени модифицировать существующие данные, например, для соблюдения регулятивных норм. Существуют два подхода для обновления или удаления данных, ни один из которых не ^^блокирует^^ параллельные вставки.
Мутации переписывают все ^^части^^ таблицы на месте. Чтобы избежать временного удвоения размера таблицы (удаление) или колонки (обновление), эта операция не является атомарной, т.е. параллельные SELECT операторы могут считывать мутированные и немутированные ^^части^^. Мутации гарантируют, что данные физически изменяются в конце операции. Мутации удаления все еще дороги, так как они переписывают все колонки во всех ^^частях^^.
В качестве альтернативы, легковесные удаления обновляют только внутренний битмап колонки, указывающий, удалена ли строка или нет. ClickHouse дополняет запросы SELECT дополнительным фильтром на битмап колонке, чтобы исключить удаленные строки из результата. Удаленные строки физически удаляются только регулярными слияниями в будущем неопределенное время. В зависимости от количества колонок легковесные удаления могут быть значительно быстрее, чем мутации, за счет более медленных SELECT.
Ожидается, что операции обновления и удаления, выполняемые на одной таблице, будут редкими и сериальными, чтобы избежать логических конфликтов.
3.5 Идемпотентные вставки
Проблема, которая часто возникает на практике, — это то, как клиентам следует обрабатывать тайм-ауты соединения после отправки данных серверу для вставки в таблицу. В данной ситуации клиентам трудно различить, были ли данные успешно вставлены или нет. Традиционно эта проблема решается повторной отправкой данных с клиента на сервер и полагается на ^^первичный ключ^^ или уникальные ограничения, чтобы отклонить дублирующие вставки. Базы данных быстро выполняют необходимые точечные запросы, используя структуры индексов на основе бинарных деревьев [39, 68], радиальных деревьев [45] или хеш-таблиц [29]. Поскольку эти структуры данных индексируют каждый кортеж, их накладные расходы на пространство и обновление становятся непосильными для больших наборов данных и высоких уровней загрузки.
ClickHouse предоставляет более легковесную альтернативу, основанную на том факте, что каждая вставка в конечном итоге создает часть. Более конкретно, сервер хранит хеши последних N вставленных ^^частей^^ (например, N=100) и игнорирует повторные вставки ^^частей^^ с известным хешом. Хеши для нереплицированных и реплицированных таблиц хранятся локально соответственно в Keeper. В результате вставки становятся идемпотентными, т.е. клиенты могут просто повторно отправить тот же пакет строк после тайм-аута и предполагать, что сервер заботится о дедупликации. Для более точного контроля над процессом дедупликации клиенты могут по желанию предоставить токен вставки, который действует как хеш части. Хотя дедупликация на основе хеша влечет за собой накладные расходы, связанные с хешированием новых строк, стоимость хранения и сравнения хешей незначительна.
3.6 Репликация данных
Репликация является предварительным условием для высокой доступности (устойчивость к сбоям узлов), но также используется для балансировки нагрузки и обновлений без простоев [14]. В ClickHouse репликация основана на понятии состояний таблицы, которые состоят из набора частей таблицы (раздел 3.1) и метаданных таблицы, таких как имена и типы колонок. Узлы обновляют состояние таблицы с помощью трех операций: 1. Вставки добавляют новую часть в состояние, 2. слияния добавляют новую часть и удаляют существующие части из состояния, 3. мутации и команды DDL добавляют части и/или удаляют части и/или изменяют метаданные таблицы в зависимости от конкретной операции. Операции выполняются локально на одном узле и фиксируются как последовательность переходов состояний в глобальном журнале репликации.
Журнал репликации поддерживается ансамблем из трех процессов ClickHouse Keeper, которые используют алгоритм консенсуса Raft [59] для обеспечения распределенного и отказоустойчивого координационного слоя для кластера узлов ClickHouse. Все узлы кластера изначально указывают на одно и то же положение в журнале репликации. В то время как узлы выполняют локальные вставки, слияния, мутации и команды DDL, журнал репликации воспроизводится асинхронно на всех других узлах. В результате, реплицированные таблицы по своей сути являются лишь в конечном итоге согласованными, т.е. узлы могут временно читать старые состояния таблицы, пока они стремятся к последнему состоянию. Большинство упомянутых операций можно также выполнять синхронно, пока не будет достигнуто большинство узлов (например, большинство узлов или все узлы), принявших новое состояние.
В качестве примера, Рисунок 6 показывает первоначально пустую реплицированную таблицу в кластере из трех узлов ClickHouse. Узел 1 сначала получает два оператора вставки и фиксирует их ( 1 2 ) в журнале репликации, хранящемся в ансамбле Keeper. Затем узел 2 воспроизводит первую запись журнала, извлекая ее ( 3 ) и загружая новую часть от узла 1 ( 4 ), в то время как узел 3 воспроизводит обе записи журнала ( 3 4 5 6 ). Наконец, узел 3 объединяет обе части в новую часть, удаляет входные части и фиксирует запись слияния в журнале репликации ( 7 ).
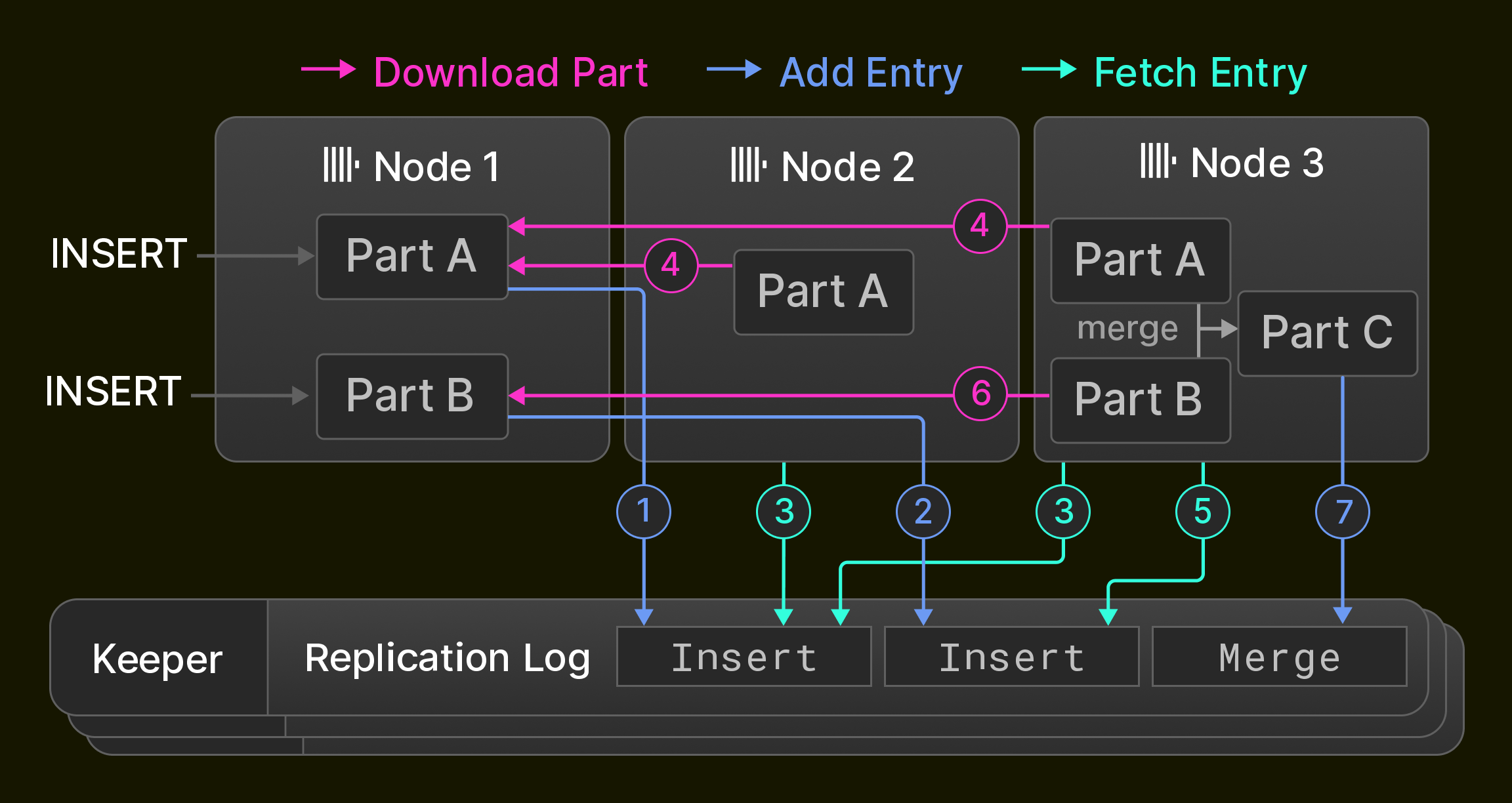
Рисунок 6: Репликация в кластере из трех узлов.
Существует три оптимизации для ускорения синхронизации: Во-первых, новые узлы, добавленные в кластер, не воспроизводят журнал репликации с нуля, вместо этого они просто копируют состояние узла, который записал последнюю запись журнала репликации. Во-вторых, слияния воспроизводятся, повторяя их локально или извлекая результирующую часть с другого узла. Точное поведение может быть настроено и позволяет балансировать потребление CPU и ввод-вывод сети. Например, репликация между датацентрами обычно предпочитает локальные слияния, чтобы минимизировать операционные расходы. В-третьих, узлы воспроизводят взаимно независимые записи журнала репликации параллельно. Это включает, например, извлечение новых частей, вставленных последовательно в одну и ту же таблицу, или операции над разными таблицами.
3.7 Соответствие ACID
Чтобы максимизировать производительность параллельных операций чтения и записи, ClickHouse избегает блокировок насколько это возможно. Запросы выполняются по снимку всех частей во всех вовлеченных таблицах, созданному в начале запроса. Это гарантирует, что новые части, вставленные параллельными INSERT или слияниями (раздел 3.1), не участвуют в выполнении. Чтобы предотвратить одновременное изменение или удаление частей (раздел 3.4), счетчик ссылок обработанных частей увеличивается на время выполнения запроса. Формально это соответствует изоляции снимков, реализованной с помощью варианта MVCC [6] на основе версионированных частей. В результате, операторы, как правило, не соответствуют ACID, за исключением редкого случая, когда конкурирующие записи в момент создания снимка затрагивают только одну часть.
На практике большинство тяжелонагруженных сценариев принятия решений в ClickHouse даже допускают небольшой риск потери новых данных в случае отключения электроэнергии. База данных использует это преимущество, не заставляя коммит (fsync) вновь вставленных частей на диск по умолчанию, что позволяет ядру объединять записи, отказавшись от атомарности.
4 УРОВЕНЬ ОБРАБОТКИ ЗАПРОСОВ
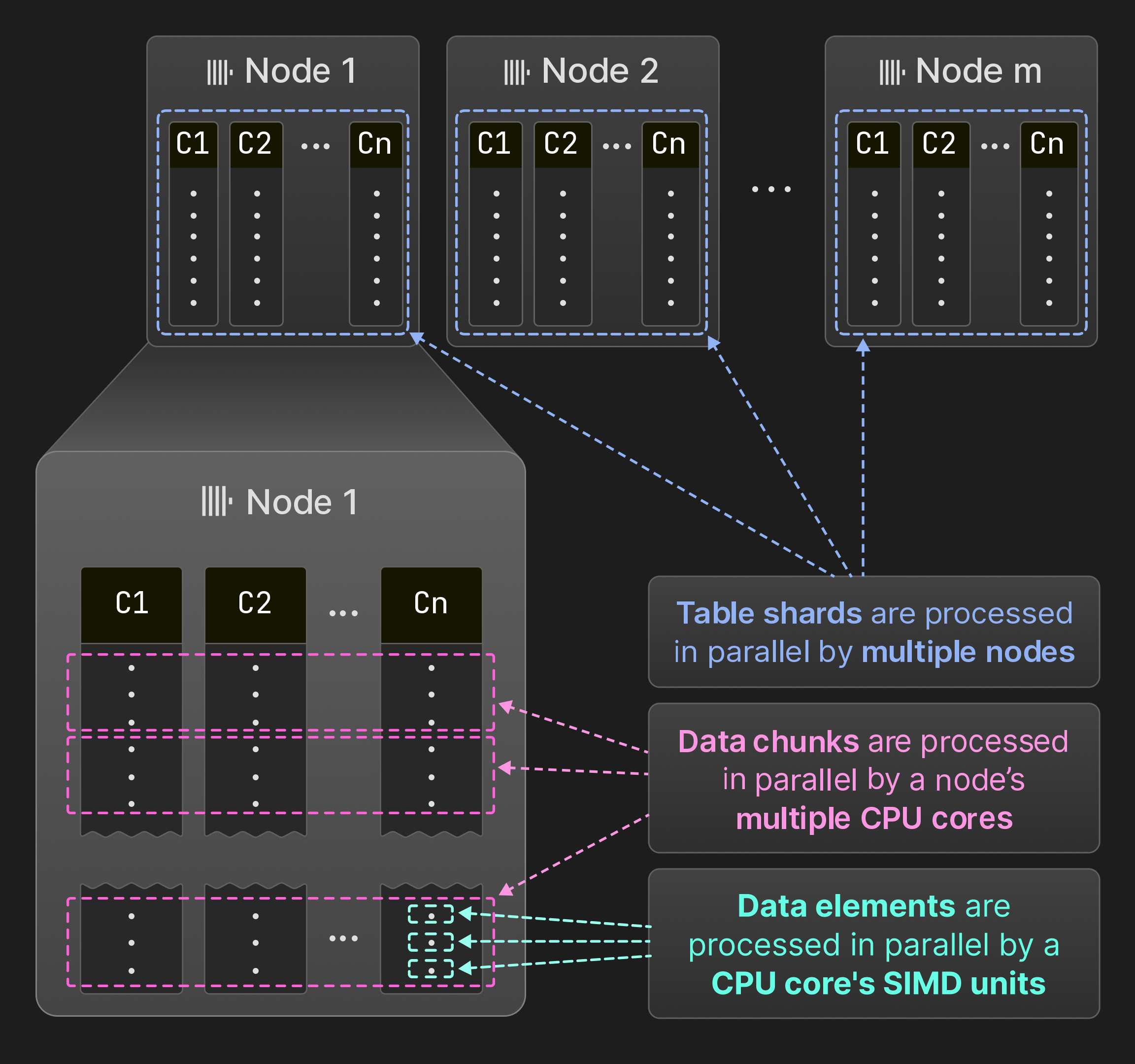
Рисунок 7: Параллелизация по SIMD единицам, ядрам и узлам.
Как показано на Рисунке 7, ClickHouse параллелизует запросы на уровне элементов данных, фрагментов данных и шардов таблицы. Множество элементов данных могут обрабатываться внутри операторов одновременно с использованием инструкций SIMD. На одном узле движок запросов выполняет операторы одновременно в нескольких потоках. ClickHouse использует ту же модель векторизации, что и MonetDB/X100 [11], т.е. операторы производят, передают и потребляют несколько строк (фрагментов данных) вместо одиночных строк, чтобы минимизировать накладные расходы на виртуальные вызовы функции. Если исходная таблица разделена на непересекающиеся шардированные таблицы, несколько узлов могут одновременно сканировать шардированные таблицы. В результате все аппаратные ресурсы используются полностью, и обработка запросов может быть горизонтально масштабирована за счет добавления узлов и вертикально за счет добавления ядер.
В остальной части этого раздела сначала будет описана параллельная обработка на уровне элементов данных, фрагментов данных и шардов более подробно. Затем мы представим выбранные ключевые оптимизации для максимизации производительности запроса. Наконец, мы обсудим, как ClickHouse управляет совместно используемыми системными ресурсами в условиях одновременных запросов.
4.1 Параллелизация SIMD
Передача множества строк между операторами создает возможность для векторизации. Векторизация основана либо на вручную написанных интринсиках [64, 80], либо на автоматической векторизации компилятора [25]. Код, который может использовать векторизацию, компилируется в различные вычислительные ядра. Например, внутренний горячий цикл оператора запроса может быть реализован в терминах не векторизованного ядра, автоматически векторизованного ядра AVX2 и вручную векторизованного ядра AVX-512. Самое быстрое ядро выбирается во время выполнения на основе инструкции cpuid. Этот подход позволяет ClickHouse работать на системах возрастом до 15 лет (требуется минимум SSE 4.2), при этом обеспечивая значительное ускорение на современном оборудовании.
4.2 Мульти-ядерная параллелизация
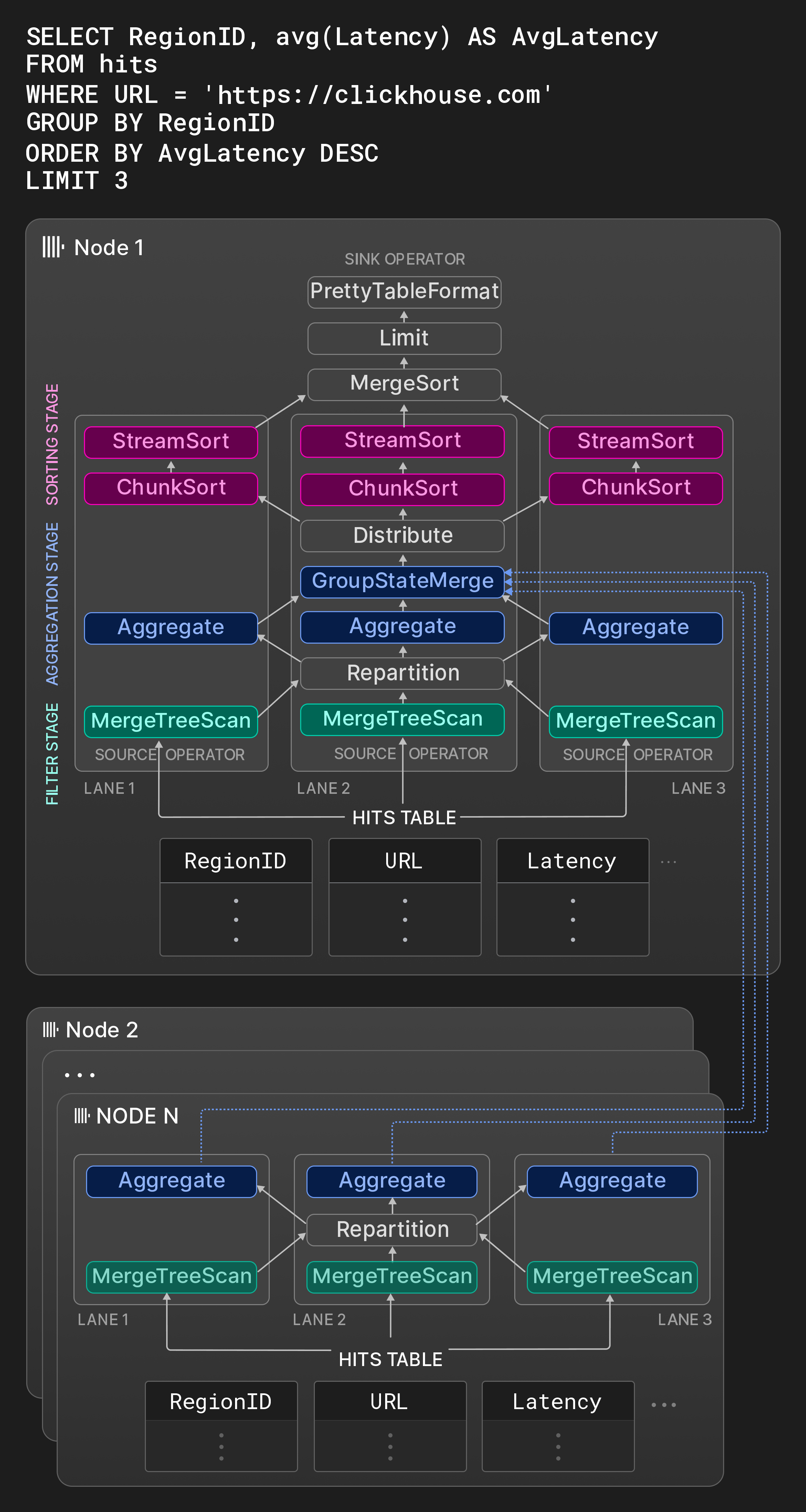
Рисунок 8: Физический план оператора с тремя потоками.
ClickHouse следует традиционному подходу [31] трансформации SQL-запросов в ориентированный граф физических операторов плана. Вход оператора плана представлен специальными источниковыми операторами, которые читают данные в родном или любом из поддерживаемых форматов сторонних производителей (см. раздел 5). Аналогичным образом, специальный оператор-сток преобразует результат в желаемый выходной формат. Физический план оператора разворачивается во время компиляции запроса в независимые исполняемые линии на основе настраиваемого максимального числа рабочих потоков (по умолчанию количество ядер) и размера исходной таблицы. Линии разлагают данные, которые будут обрабатываться параллельными операторами, на непересекающиеся диапазоны. Чтобы максимизировать возможности для параллельной обработки, линии объединяются как можно позже.
В качестве примера, рамка для узла 1 на Рисунке 8 показывает граф операторов типичного OLAP-запроса к таблице со статистикой показов страниц. На первом этапе три непересекающихся диапазона исходной таблицы фильтруются одновременно. Оператор обмена Repartition динамически маршрутизирует результирующие фрагменты между первым и вторым этапами для поддержания равномерной загрузки потоков обработки. Линии могут стать несбалансированными после первого этапа, если отсканированные диапазоны имеют значительно разные селективности. На втором этапе строки, которые прошли фильтр, группируются по RegionID. Операторы Aggregate поддерживают локальные группы результатов с RegionID в качестве группировочной колонки и сумму и счет для каждой группы в качестве частичного состояния агрегации для avg(). Локальные результаты агрегации в конечном итоге объединяются оператором GroupStateMerge в глобальный результат агрегации. Этот оператор также является разрывом в конвейере, т.е. третий этап может начаться только после полной обработки результата агрегации. На третьем этапе группы результатов сначала делятся оператором Exchange на три равные непересекающиеся части, которые затем сортируются по AvgLatency. Сортировка выполняется в три этапа: во-первых, операторы ChunkSort сортируют отдельные фрагменты каждой части. Во-вторых, операторы StreamSort поддерживают локальный отсортированный результат, который объединяется с поступающими отсортированными фрагментами с использованием двухходовой сортировки слиянием. Наконец, оператор MergeSort объединяет локальные результаты, используя k-ходовую сортировку для получения окончательного результата.
Операторы являются конечными автоматами и соединены друг с другом через входные и выходные порты. Три возможных состояния оператора – need-chunk, ready и done. Для перехода из need-chunk в ready фрагмент помещается в входной порт оператора. Для перехода из ready в done оператор обрабатывает входной фрагмент и генерирует выходной фрагмент. Для перехода из done в need-chunk выходной фрагмент удаляется из выходного порта оператора. Переходы первого и третьего состояний в двух связанных операторах могут быть выполнены только в одном объединенном шаге. Исходные операторы (операторы-стоки) имеют только состояния ready и done (need-chunk и done).
Рабочие потоки непрерывно перемещаются по физическому оператору плана и выполняют переходы состояний. Чтобы поддерживать горячими кэши CPU, план содержит подсказки о том, что один и тот же поток должен обрабатывать последовательные операторы в одной линии. Параллельная обработка происходит как горизонтально по непересекающимся входам внутри этапа (например, на Рисунке 8 операторы Aggregate выполняются одновременно), так и вертикально по этапам, не разделенным разрывами конвейера (например, на Рисунке 8 оператор Filter и оператор Aggregate в одной линии могут работать одновременно). Чтобы избежать превышения и недостатка подписки, когда начинаются новые запросы или завершаются параллельные запросы, степень параллелизма может быть изменена в процессе запроса между одним и максимальным количеством рабочих потоков для запроса, указанным в начале запроса (см. раздел 4.5).
Операторы также могут дополнительно влиять на выполнение запроса во время выполнения двумя способами. Во-первых, операторы могут динамически создавать и подключать новые операторы. Это в основном используется для переключения на внешние алгоритмы агрегации, сортировки или соединения вместо отмены запроса, когда потребление памяти превышает настраиваемый порог. Во-вторых, операторы могут запрашивать рабочие потоки, чтобы переместиться в асинхронную очередь. Это обеспечивает более эффективное использование рабочих потоков, когда они ждут удаленных данных.
Движок выполнения запросов ClickHouse и параллелизм на основе кусочков [44] схожи тем, что линии, как правило, выполняются на разных ядрах / сокетах NUMA и что рабочие потоки могут заимствовать задачи из других линий. Кроме того, нет центрального компонента планирования; вместо этого рабочие потоки выбирают свои задачи индивидуально, непрерывно проходя по операторному плану. В отличие от параллелизма на основе кусочков, ClickHouse закладывает максимальную степень параллелизма в план и использует гораздо большие диапазоны для разбиения исходной таблицы по сравнению с размерами кусочков по умолчанию около 100.000 строк. Хотя это может в некоторых случаях вызвать задержки (например, когда время выполнения операторов фильтра в разных линиях сильно различается), мы обнаружили, что широкое использование операторов обмена, таких как Repartition, по крайней мере позволяет избежать накопления таких несбалансированностей между этапами.
4.3 Параллелизация на нескольких узлах
Если исходная таблица запроса разделена на шардированные части, оптимизатор запросов на узле, получившем запрос (инициирующий узел), пытается выполнить как можно больше работы на других узлах. Результаты с других узлов могут быть интегрированы в различных точках плана запроса. В зависимости от запроса удаленные узлы могут либо 1. передавать сырые колонки исходной таблицы на инициирующий узел, 2. фильтровать исходные колонки и отправлять оставшиеся строки, 3. выполнять фильтрацию и шаги агрегации и отправлять локальные группы результатов с частичными состояниями агрегации, либо 4. выполнять весь запрос, включая фильтры, агрегацию и сортировку.
Узлы 2 ... N на Рисунке 8 показывают фрагменты плана, выполняемые на других узлах, содержащих шарды таблицы hits. Эти узлы фильтруют и группируют локальные данные и отправляют результат инициирующему узлу. Оператор GroupStateMerge на узле 1 объединяет локальные и удаленные результаты перед окончательной сортировкой групп результатов.
4.4 Целостная оптимизация производительности
Этот раздел представляет избранные ключевые оптимизации производительности, применяемые на различных этапах выполнения запроса.
Оптимизация запросов. Первый набор оптимизаций применяется к семантическому представлению запроса, полученному из AST запроса. Примеры таких оптимизаций включают свертку констант (например, concat(lower('a'), upper('b')) становится 'aB'), извлечение скаляров из определенных агрегатных функций (например, sum(a * 2) становится 2 * sum(a)), устранение общих подвыражений и преобразование дизъюнкций фильтров равенства в списки IN (например, x=c OR x=d становится x IN (c, d)). Оптимизированное семантическое представление запроса затем преобразуется в логический операторный план. Оптимизации выше логического плана включают продвижение фильтров, изменение порядка оценивания функций и шагов сортировки в зависимости от того, какой из них предполагается быть более затратным. В конце логический запросный план преобразуется в физический план оператора. Это преобразование может использовать особенности вовлеченных движков таблиц. Например, в случае движка таблиц ^^MergeTree^^, если колонки ORDER BY формируют префикс первичного ключа, данные могут быть прочитаны в порядке диска, и операторы сортировки могут быть удалены из плана. Кроме того, если колонки группировки в агрегации формируют префикс первичного ключа, ClickHouse может использовать сортировочную агрегацию [33], т.е. агрегировать последовательности одного и того же значения в предсортированных входах напрямую. По сравнению с хеш-агрегацией, сортировочная агрегация значительно менее требовательна к памяти, и агрегированное значение может быть передано следующему оператору сразу после обработки последовательности.
Компиляция запросов. ClickHouse использует компиляцию запросов на основе LLVM для динамического объединения смежных операторов плана [38, 53]. Например, выражение a * b + c + 1 может быть объединено в один оператор вместо трех операторов. Кроме выражений, ClickHouse также использует компиляцию для одновременной оценки нескольких агрегатных функций (т.е. для GROUP BY) и для сортировки с более чем одним ключом сортировки. Компиляция запроса уменьшает количество виртуальных вызовов, поддерживает данные в регистрах или кэшах CPU и помогает предсказателю ветвлений, так как требуется выполнять менее кода. Кроме того, компиляция во время выполнения позволяет использовать широкий набор оптимизаций, таких как логические оптимизации и оптимизации на уровне зрения, реализуемые в компиляторах, и дает доступ к самым быстрым доступным инструкциям CPU. Компиляция инициируется только тогда, когда одно и то же регулярное, агрегатное или сортировочное выражение выполняется разными запросами более чем заданное число раз. Скомпилированные операторы запросов кэшируются и могут быть повторно использованы в последующих запросах.[7]
Оценка индекса ^^первичного ключа^^. ClickHouse оценивает условия WHERE, используя индекс ^^первичного ключа^^, если подмножество фильтров в конъюнктивной нормальной форме условия составляет префикс колонок ^^первичного ключа^^. Индекс ^^первичного ключа^^ анализируется слева направо по лексикографически отсортированным диапазонам ключевых значений. Фильтры, соответствующие колонке ^^первичного ключа^^, оцениваются с использованием тернарной логики - они могут быть все истинными, все ложными или смешанными истинными/ложными для значений в диапазоне. В последнем случае диапазон разбивается на поддиапазоны, которые анализируются рекурсивно. Дополнительные оптимизации существуют для функций в условиях фильтрации. Во-первых, функции имеют характеристики, описывающие их монотонность, например, toDayOfMonth(date) является кусочно монотонной в пределах месяца. Характеристики монотонности позволяют выяснить, производит ли функция отсортированные результаты на отсортированных входных диапазонах значений ключей. Во-вторых, некоторые функции могут вычислять прообраз данного результата функции. Это используется для замены сравнений констант вызовами функций по ключевым колонкам путем сравнения значения ключевой колонки с прообразом. Например, toYear(k) = 2024 может быть заменено на k >= 2024-01-01 && k < 2025-01-01.
Пропуск данных. ClickHouse старается избегать чтения данных во время выполнения запроса, используя структуры данных, представленные в разделе 3.2. Кроме того, фильтры по различным колонкам оцениваются последовательно в порядке убывания предполагаемой селективности на основе эвристик и (необязательной) статистики колонок. Только те фрагменты данных, которые содержат хотя бы одну совпадающую строку, передаются в следующий предикат. Это постепенно уменьшает количество считываемых данных и количество вычислений, которые необходимо выполнить от предиката к предикату. Оптимизация применяется только тогда, когда присутствует хотя бы один высокоселективный предикат; в противном случае задержка запроса ухудшилась бы по сравнению с оценкой всех предикатов параллельно.
Хеш-таблицы. Хеш-таблицы являются основными структурами данных для агрегации и хеш-соединений. Выбор правильного типа хеш-таблицы критически важен для производительности. ClickHouse инстанцирует различные хеш-таблицы (более 30 на март 2024) из шаблона общей хеш-таблицы с хеш-функцией, выделителем, типом ячейки и политикой изменения размера как вариационными точками. В зависимости от типа данных колонок группировки, предполагаемой кардинальности хеш-таблицы и других факторов для каждого оператора запроса индивидуально выбирается самая быстрая хеш-таблица. Дополнительные оптимизации, реализованные для хеш-таблиц, включают:
- двуступенчатая компоновка с 256 подсчетами (на основе первого байта хеша) для поддержки огромных наборов ключей,
- хеш-таблицы строк [79] с четырьмя подсчетами и разными хеш-функциями для различных длин строк,
- таблицы поиска, которые используют ключ непосредственно в качестве индекса корзины (т.е. без хеширования), когда имеется лишь несколько ключей,
- значения с встроенными хешами для более быстрого разрешения коллизий, когда сравнение дорого (например, строки, AST),
- создание хеш-таблиц на основе прогнозируемых размеров из статистики времени выполнения, чтобы избежать ненужных изменений размера,
- выделение нескольких маленьких хеш-таблиц с одинаковым циклом создания/уничтожения на одном участке памяти,
- мгновенное очищение хеш-таблиц для повторного использования с использованием счетчиков версий для каждой хеш-карты и для каждой ячейки,
- использование предварительной выборки CPU (__builtin_prefetch) для ускорения получения значений после хеширования ключа.
Соединения. Поскольку ClickHouse изначально поддерживал соединения только в элементарной форме, многие сценарии исторически прибегали к деноормализованным таблицам. В настоящее время база данных предлагает все типы соединений, доступные в SQL (внутренние, левые/правые/полные внешние, перекрестные, по состоянию на), а также различные алгоритмы соединений, такие как хеш-соединение (наивное, грейс), сортировочно-сливаемое соединение и индексное соединение для движков таблиц с быстрым доступом к ключ-значение (обычно словарям).
Поскольку соединения являются одними из самых дорогих операций баз данных, важно предоставлять параллельные варианты классических алгоритмов соединения, желательно с настраиваемыми компромиссами по пространству/времени. Для хеш-соединений ClickHouse реализует неблокирующий алгоритм разделения с совместным доступом [7]. Например, запрос на Рисунке 9 вычисляет, как пользователи перемещаются между URL-адресами с помощью само-соединения на таблице статистики посещений страниц. Этап построения соединения разбивается на три линии, охватывающие три непересекающихся диапазона исходной таблицы. Вместо глобальной хеш-таблицы используется разделенная хеш-таблица. Рабочие потоки (обычно три) определяют целевую партию для каждой входной строки строящей стороны, вычисляя модуль хеш-функции. Доступ к разделам хеш-таблицы синхронизируется с помощью операторов обмена Gather. Этап пробирования находит целевую партию для своих входных кортежей аналогично. Хотя этот алгоритм вводит две дополнительные хеш-вычислений на каждом кортеже, он значительно снижает конкуренцию за захват в фазе построения, в зависимости от количества разделов хеш-таблицы.
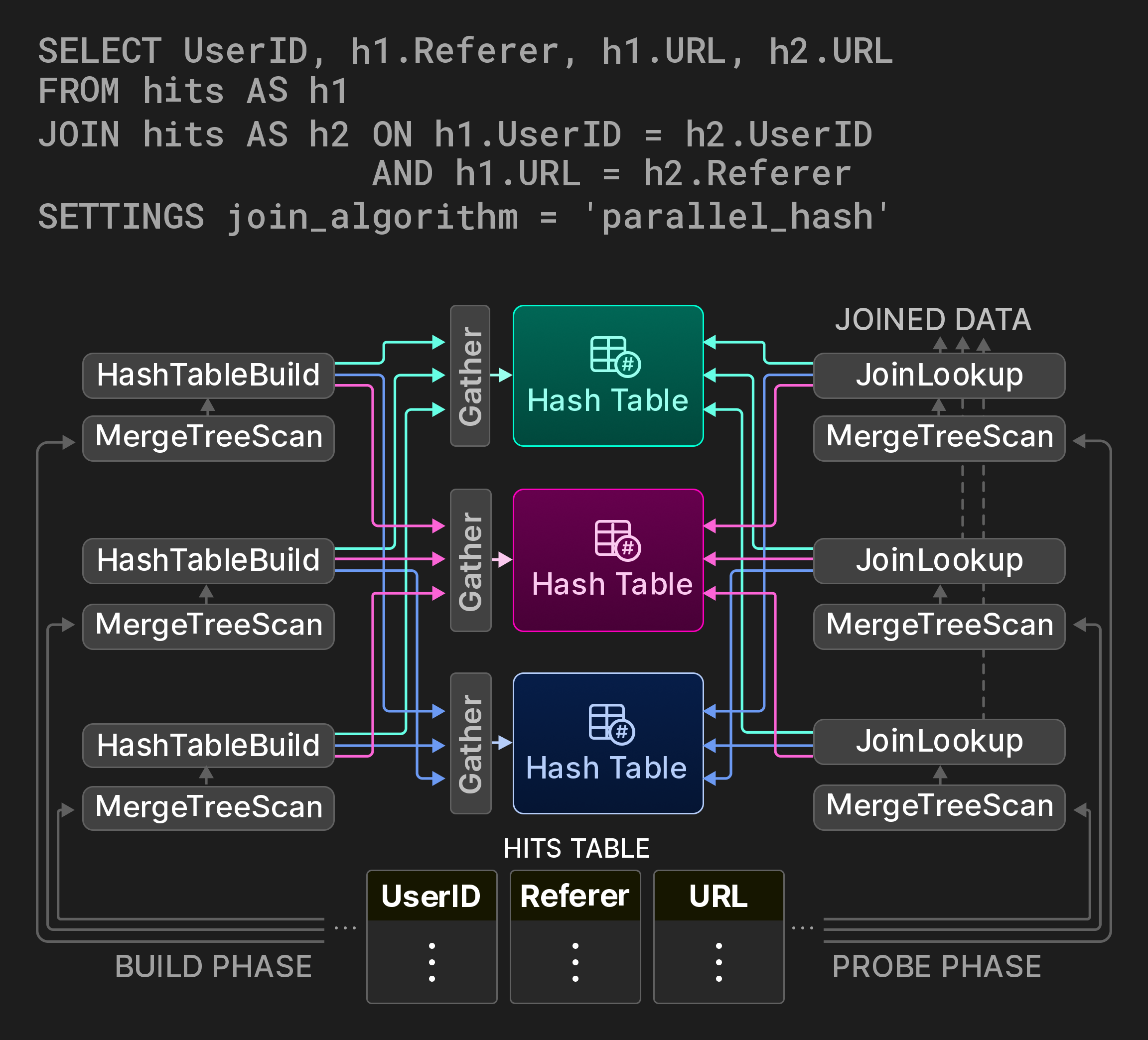
Рисунок 9: Параллельное хеш-соединение с тремя разделами хеш-таблицы.
4.5 Изоляция нагрузки
ClickHouse предлагает управление одновременно выполняемыми запросами, ограничения по использованию памяти и планирование ввода-вывода, позволяя пользователям изолировать запросы в классы нагрузки. Устанавливая ограничения на совместно используемые ресурсы (ядра CPU, ОЗУ, ввод-вывод диска и сети) для конкретных классов нагрузки, он обеспечивает, чтобы эти запросы не влияли на другие критически важные бизнес-запросы.
Контроль параллельности предотвращает переувеличение потоков в сценариях с высоким количеством одновременно выполняемых запросов. Более конкретно, количество рабочих потоков на запрос динамически регулируется в зависимости от указанного соотношения к количеству доступных ядер CPU.
ClickHouse отслеживает размер байтов выделяемой памяти на уровне сервера, пользователя и запроса, и тем самым позволяет устанавливать гибкие лимиты использования памяти. Переоценка памяти позволяет запросам использовать дополнительную свободную память сверх гарантированной памяти, одновременно обеспечивая лимиты памяти для других запросов. Более того, использование памяти для агрегации, сортировки и условий соединения может быть ограничено, что приводит к переходу на внешние алгоритмы при превышении лимита памяти.
Наконец, планирование ввода-вывода позволяет пользователям ограничивать доступы к локальным и удаленным дискам для классов нагрузки на основе максимальной пропускной способности, запросов в процессе и политики (например, FIFO, SFC [32]).
5 УРОВЕНЬ ИНТЕГРАЦИИ
Приложения для принятия решений в реальном времени часто зависят от эффективного и низкозадерживающего доступа к данным в нескольких местах. Существует два подхода, чтобы сделать внешние данные доступными в OLAP базе данных. В модели с доступом по выталкиванию компонент третьей стороны соединяет базу данных с внешними хранилищами данных. Одним примером таких являются специализированные инструменты для извлечения-трансформации-загрузки (ETL), которые передают удаленные данные в целевую систему. В модели с доступом по подтягиванию база данных сама подключается к удаленным источникам данных и извлекает данные для запросов в локальные таблицы или экспортирует данные в удаленные системы. В то время как методы на основе вытягивания более универсальны и распространены, они относятся к большему архитектурному следу и узкым местам масштабируемости. Напротив, удаленное подключение непосредственно в базе данных предлагает интересные возможности, такие как соединения между локальными и удаленными данными, при этом сохраняя общую архитектуру простой и сокращая время до получения информации.
В остальной части раздела рассматриваются методы интеграции данных на основе подтягивания в ClickHouse, направленные на доступ к данным в удаленных местах. Мы отмечаем, что идея удаленного подключения в SQL базах данных не нова. Например, стандарт SQL/MED [35], введенный в 2001 году и реализованный в PostgreSQL с 2011 года [65], предлагает обертки для внешних данных как единый интерфейс для управления внешними данными. Максимальная совместимость с другими хранилищами данных и форматами хранения является одной из целей проектирования ClickHouse. На март 2024 года ClickHouse предлагает, наилучшим образом, наиболее встроенные возможности интеграции данных среди всех аналитических баз данных.
Внешняя связность. ClickHouse предоставляет более 50 функций таблиц интеграции и движков для взаимодействия с внешними системами и хранилищами данных, включая ODBC, MySQL, PostgreSQL, SQLite, Kafka, Hive, MongoDB, Redis, объекты S3/GCP/Azure и различные ДатаЛэйки. Мы разбиваем их дальше на категории, представленные последующим бонусным рисунком (не частью оригинальной статьи vldb).
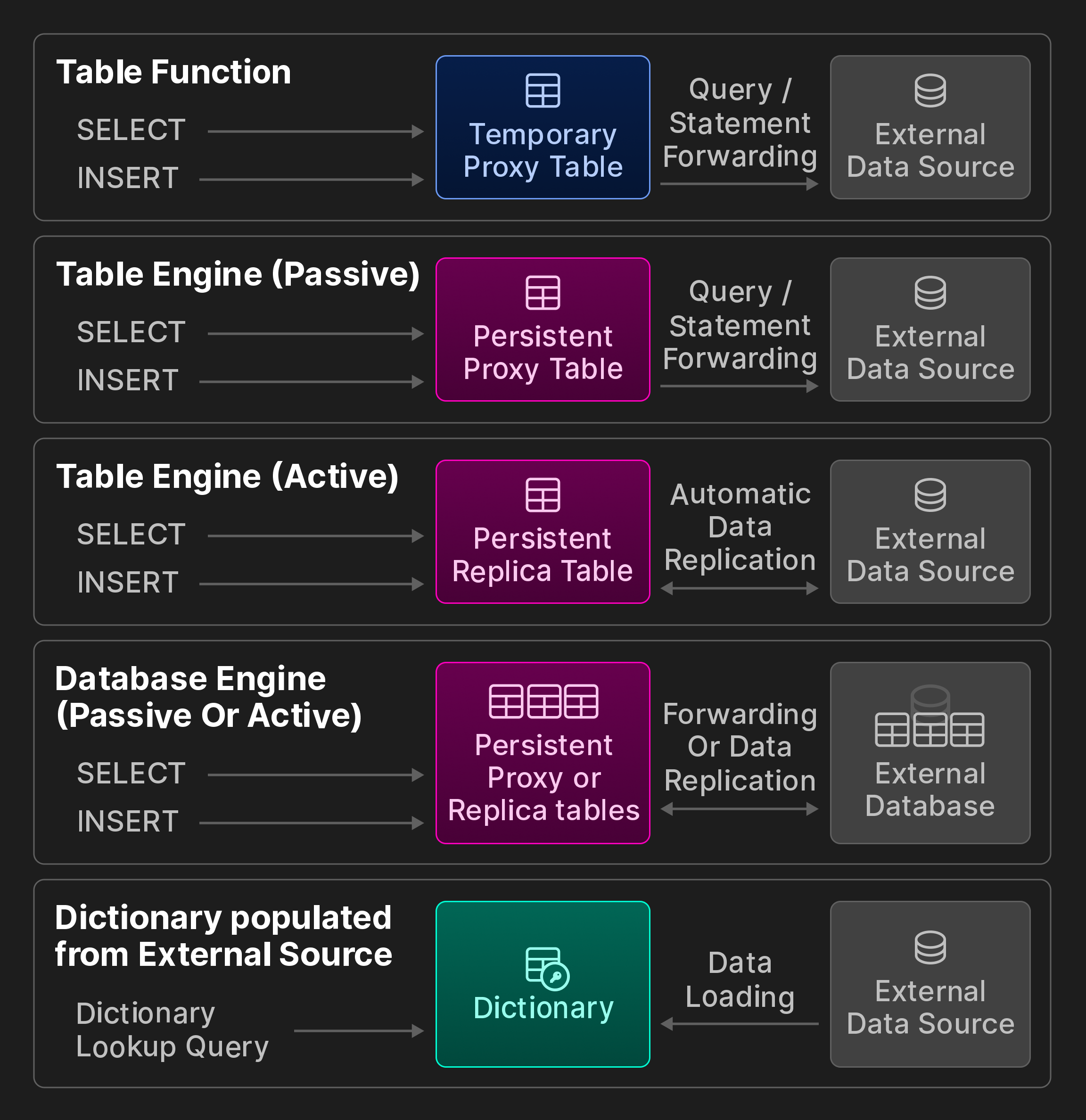
Бонусный рисунок: Опции взаимосвязи ClickBench.
Временный доступ с использованием Функций Таблиц Интеграции. Функции таблиц могут быть вызваны в клаузе FROM SQL запросов для чтения удаленных данных для исследовательских запросов. В качестве альтернативы они могут быть использованы для записи данных в удаленные хранилища с помощью операторов INSERT INTO TABLE FUNCTION.
Постоянный доступ. Существуют три метода для создания постоянных соединений с удаленными хранилищами и системами обработки данных.
Во-первых, интеграционные движки таблиц представляют удаленный источник данных, такой как таблица MySQL, в виде постоянной локальной таблицы. Пользователи хранят определение таблицы, используя синтаксис CREATE TABLE AS, в сочетании с запросом SELECT и функцией таблицы. Возможность указать собственную схему, например, для ссылки только на подмножество удаленных колонок, или использовать вывод схемы для автоматического определения имен колонок и эквивалентных типов ClickHouse. Мы дополнительно различаем пассивное и активное поведение во время выполнения: Пассивные движки таблиц передают запросы удаленной системе и заполняют локальную прокси-таблицу результатами. В отличие от этого, активные движки таблиц периодически извлекают данные из удаленной системы или подписываются на удаленные изменения, например, через протокол логической репликации PostgreSQL. В результате локальная таблица содержит полную копию удаленной таблицы.
Во-вторых, интеграционные движки баз данных отображают все таблицы схемы таблицы в удаленном хранилище данных в ClickHouse. В отличие от предыдущего, они, как правило, требуют, чтобы удаленное хранилище данных было реляционной базой данных и дополнительно предоставляет ограниченную поддержку операторов DDL.
В-третьих, словаря могут заполняться с помощью произвольных запросов против почти всех возможных источников данных с соответствующей функцией или движком интеграции. Поведение во время выполнения является активным, так как данные извлекаются с постоянными интервалами из удаленного хранилища.
Форматы данных. Для взаимодействия с системами третьих сторон современные аналитические базы данных также должны уметь обрабатывать данные в любом формате. Поммимо собственного формата, ClickHouse поддерживает более 90 форматов, включая CSV, JSON, Parquet, Avro, ORC, Arrow и Protobuf. Каждый формат может быть как входным (который ClickHouse может прочитать), выходным (который ClickHouse может экспортировать), или и тем и другим. Некоторые ориентированные на аналитику форматы, такие как Parquet, также интегрированы с обработкой запросов, т.е. оптимизатор может использовать встроенную статистику, а фильтры оцениваются сразу на сжатых данных.
Интерфейсы совместимости. Помимо собственного двоичного протокола передачи и HTTP, клиенты могут взаимодействовать с ClickHouse через интерфейсы, совместимые с протоколами передачи MySQL или PostgreSQL. Эта функция совместимости полезна для обеспечения доступа из проприетарных приложений (например, некоторых инструментов бизнес-аналитики), где поставщики еще не реализовали нативное подключение ClickHouse.
6 ПРОИЗВОДИТЕЛЬНОСТЬ КАК ФУНКЦИЯ
В этом разделе представлены встроенные инструменты для анализа производительности и оценка производительности с использованием реальных и ориентированных на бенчмарки запросов.
6.1 Встроенные инструменты анализа производительности
Широкий спектр инструментов доступен для исследования узких мест производительности в отдельных запросах или фоновых операциях. Пользователи взаимодействуют со всеми инструментами через единый интерфейс на основе системных таблиц.
Метрики сервера и запросов. Статистика на уровне сервера, такие как количество активных частей, пропускная способность сети и коэффициенты попадания в кэш, дополняется статистикой по запросам, например, количеством считанных блоков или статистикой использования индексов. Метрики вычисляются синхронно (по запросу) или асинхронно с настраиваемыми интервалами.
Сэмплинг профайлер. Стек вызовов потоков сервера можно собрать с помощью профайлера выборки. Результаты могут дополнительно экспортироваться во внешние инструменты, такие как визуализаторы Flamegraph.
Интеграция OpenTelemetry. OpenTelemetry является открытым стандартом для трассировки строк данных через несколько систем обработки данных [8]. ClickHouse может генерировать интервалы логов OpenTelemetry с настраиваемой Granularity для всех шагов обработки запроса, а также собирать и анализировать интервалы логов OpenTelemetry из других систем.
Объяснение запроса. Как и в других базах данных, запросы SELECT могут быть предшествованы оператором EXPLAIN для подробной информации о AST запроса, логическом и физическом планах операторов и поведении во время выполнения.
6.2 Бенчмарки
Хотя бенчмарки подвергались критике за недостаточную реалистичность [10, 52, 66, 74], они по-прежнему полезны для выявления сильных и слабых сторон баз данных. В следующем разделе мы обсудим, как используются бенчмарки для оценки производительности ClickHouse.
6.2.1 Денормализованные таблицы
Фильтры и запросы агрегации по денормализованным фактическим таблицам исторически представляют собой основной случай использования ClickHouse. Мы представляем время выполнения ClickBench, типичной нагрузки такого рода, которая моделирует по запросу и периодической отчётности, используемой в анализе кликов и трафика. Бенчмарк состоит из 43 запросов к таблице с 100 миллионами анонимизированных переходов по страницам, полученных от одной из крупнейших аналитических платформ в интернете. Онлайн панели управления [17] показывают измерения (холодное/горячее время выполнения, время импорта данных, размер на диске) для более чем 45 коммерческих и исследовательских баз данных на июнь 2024 года. Результаты предоставлены независимыми добровольцами на основе общедоступного набора данных и запросов [16]. Запросы тестируют последовательные и индексовые пути доступа и регулярно выявляют операторы реляционных баз данных, привязанные к CPU, I/O или памяти.
Рисунок 10 показывает общее относительное холодное и горячее время выполнения для последовательного выполнения всех запросов ClickBench в базах данных, которые часто используются для аналитики. Измерения проводились на одном узле AWS EC2 c6a.4xlarge с 16 vCPUs, 32 ГБ ОЗУ и 5000 IOPS / 1000 MiB/s диском. Сравнимые системы использовались для Redshift (ra3.4xlarge, 12 vCPUs, 96 ГБ ОЗУ) и Snowfake (размер склада S: 2x8 vCPUs, 2x16 ГБ ОЗУ). Физический дизайн базы данных настраивается только немного, например, мы указываем первичные ключи, но не изменяем сжатие отдельных колонок, не создаем проекции и индексы пропуска. Мы также сбрасываем кэш страниц Linux перед каждым запуском холодного запроса, но не настраиваем параметры базы данных или операционной системы. Для каждого запроса максимальное время выполнения среди баз данных используется в качестве эталона. Относительное время выполнения запросов для других баз данных вычисляется как ( + 10)/(_ + 10). Общее относительное время выполнения для базы данных – это геометрическое среднее отношения по запросам. Хотя исследовательская база данных Umbra [54] достигает наилучшего общего горячего времени выполнения, ClickHouse превосходит все другие производственные базы данных по горячему и холодному времени выполнения.
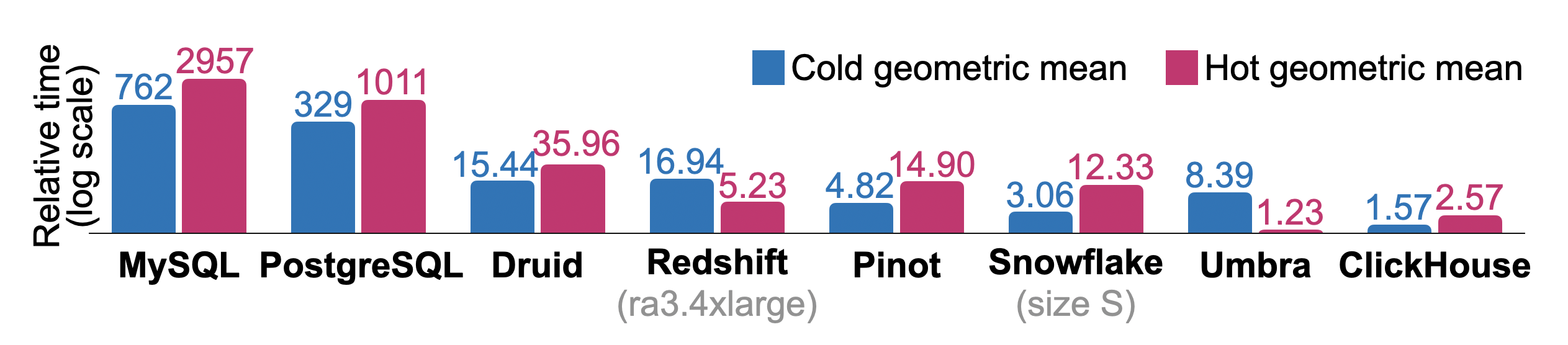
Рисунок 10: Относительное холодное и горячее время выполнения ClickBench.
Чтобы отслеживать производительность SELECT-запросов в более разнообразных нагрузках с течением времени, мы используем комбинацию из четырёх бенчмарков под названием VersionsBench [19]. Этот бенчмарк выполняется раз в месяц, когда публикуется новое обновление, чтобы оценить его производительность [20] и выявить изменения в коде, которые могут ухудшить производительность: индивидуальные бенчмарки включают: 1. ClickBench (описанный выше), 2. 15 запросов MgBench [21], 3. 13 запросов к денормализованной таблице фактов Star Schema Benchmark [57] с 600 миллионами строк. 4. 4 запроса к NYC Taxi Rides с 3.4 миллиарда строк [70].
Рисунок 11 показывает развитие времени выполнения VersionsBench для 77 версий ClickHouse с марта 2018 года по март 2024 года. Чтобы компенсировать различия в относительном времени выполнения отдельных запросов, мы нормализуем времена выполнения, используя геометрическое среднее с соотношением к минимальному времени выполнения запроса среди всех версий в качестве веса. Производительность VersionBench улучшилась на 1.72 × за последние шесть лет. Даты для релизов с долгосрочной поддержкой (LTS) отмечены на оси x. Хотя производительность временно ухудшалась в некоторые периоды, LTS-релизы как правило имеют сопоставимую или лучшую производительность, чем предыдущая версия LTS. Значительное улучшение в августе 2022 года было вызвано техникой оценки фильтров по столбцам, описанной в разделе 4.4.
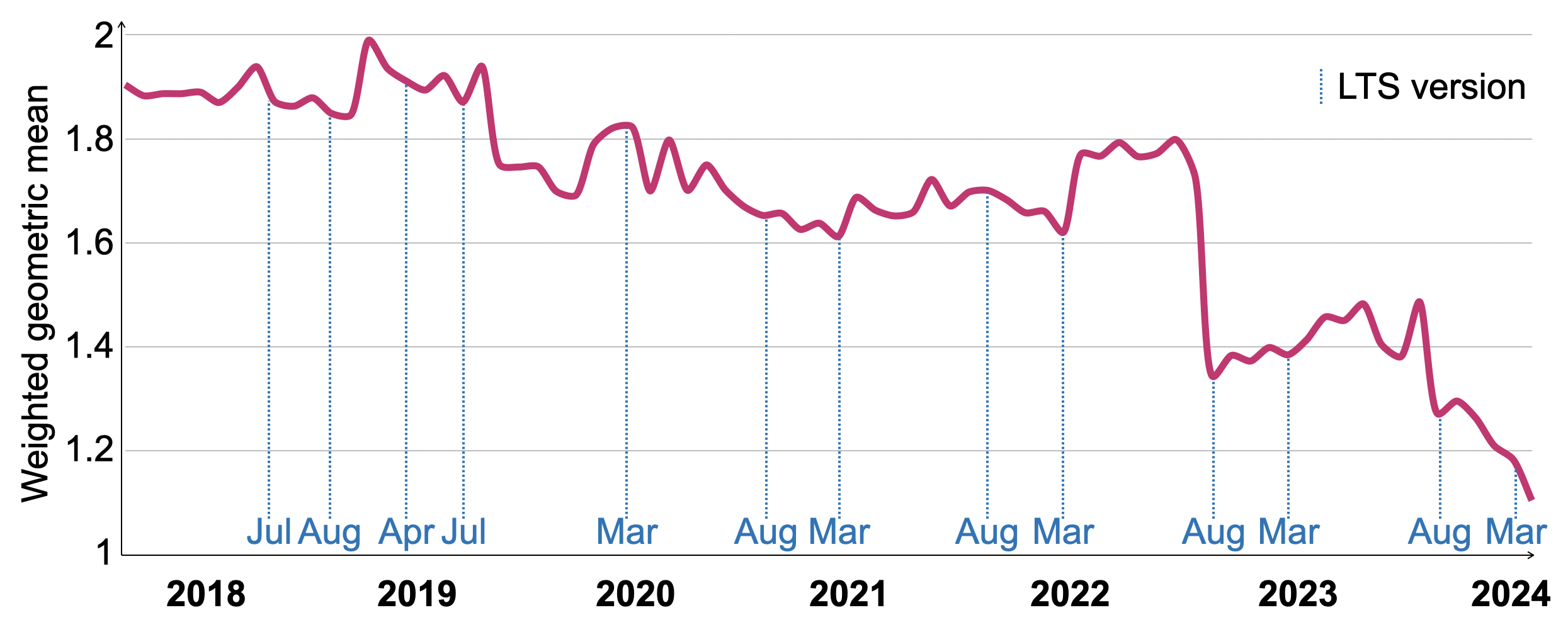
Рисунок 11: Относительные горячие времена выполнения VersionsBench 2018-2024.
6.2.2 Нормализованные таблицы
В классическом хранилище данные часто моделируются с использованием схем звезд или снежинок. Мы представляем время выполнения запросов TPC-H (коэффициент масштаба 100), но замечаем, что нормализованные таблицы являются новым случаем использования для ClickHouse. Рисунок 12 показывает горячие времена выполнения запросов TPC-H на основе параллельного алгоритма хеширования, описанного в разделе 4.4.. Измерения проводились на одном узле AWS EC2 c6i.16xlarge с 64 vCPUs, 128 ГБ ОЗУ и 5000 IOPS / 1000 MiB/s диском. Зафиксировано время выполнения самого быстрого из пяти запусков. Для справки мы выполнили те же измерения в системе Snowfake сопоставимого размера (размер склада L, 8x8 vCPUs, 8x16 ГБ ОЗУ). Результаты одиннадцати запросов исключены из таблицы: Запросы Q2, Q4, Q13, Q17 и Q20-22 включают коррелированные подзапросы, которые не поддерживаются на версии ClickHouse v24.6. Запросы Q7-Q9 и Q19 зависят от расширенных оптимизаций на уровне плана для соединений, таких как перестановка соединений и пропуск предикатов соединения (обе отсутствуют на ClickHouse v24.6.) для достижения жизнеспособного времени выполнения. Автоматическая декорреляция подзапросов и лучшая поддержка оптимизатора для соединений планируются к реализации в 2024 году [18]. Из оставшихся 11 запросов 5 (6) запросов были выполнены быстрее в ClickHouse (Snowfake). Поскольку вышеуказанные оптимизации известны как критически важные для производительности [27], мы ожидаем, что они дополнительно улучшат время выполнения этих запросов после их реализации.

Рисунок 12: Горячие времена выполнения (в секундах) для запросов TPC-H.
7 СВЯЗАННЫЕ РАБОТЫ
Аналитические базы данных пользовались большим академическим и коммерческим интересом в последние десятилетия [1]. Ранние системы, такие как Sybase IQ [48], Teradata [72], Vertica [42] и Greenplum [47], характеризовались дорогостоящими пакетными работами ETL и ограниченной эластичностью из-за своей локальной природы. В начале 2010-х годов появление облачных хранилищ данных и предложений базы данных как услуги (DBaaS), таких как Snowfake [22], BigQuery [49] и Redshift [4], резко снизило стоимость и сложность аналитики для организаций, при этом обеспечивая высокую доступность и автоматическое масштабирование ресурсов. В последнее время аналитические ядра выполнения (например, Photon [5] и Velox [62]) предлагают совместно модифицированную обработку данных для использования в различных аналитических, потоковых и машинных обучающих приложениях.
Наиболее схожими с ClickHouse по целям и принципам проектирования являются Druid [78] и Pinot [34]. Оба систем нацелены на аналитику в реальном времени с высокими ставками приема данных. Как и ClickHouse, таблицы делятся на горизонтальные ^^части^^, называемые сегментами. В то время как ClickHouse постоянно объединяет меньшие ^^части^^ и, при необходимости, уменьшает объем данных с использованием техник, описанных в разделе 3.3, ^^части^^ остаются навсегда неизменными в Druid и Pinot. Кроме того, Druid и Pinot требуют специализированные узлы для создания, мутации и поиска таблиц, в то время как ClickHouse использует монолитный бинарный файл для этих задач.
Snowfake [22] является популярным проприетарным облачным хранилищем данных, основанным на архитектуре общего диска. Его подход к делению таблиц на микрочасти аналогичен концепции ^^частей^^ в ClickHouse. Snowfake использует гибридные страницы PAX [3] для хранения, в то время как формат хранения ClickHouse строго столбцовый. Snowfake также подчеркивает локальное кэширование и обрезку данных с использованием автоматически создаваемых легковесных индексов [31, 51] в качестве источника хорошей производительности. Подобно первичным ключам в ClickHouse, пользователи могут по желанию создавать кластерные индексы для совмещения данных с одинаковыми значениями.
Photon [5] и Velox [62] являются движками выполнения запросов, разработанными для использования в качестве компонентов в сложных системах управления данными. Обе системы принимают планы запросов в качестве входных данных, которые затем выполняются на локальном узле с использованием файлов Parquet (Photon) или Arrow (Velox) [46]. ClickHouse способен потреблять и генерировать данные в этих универсальных форматах, но предпочитает свой собственный файловый формат для хранения. Хотя Velox и Photon не оптимизируют план запроса (Velox выполняет базовые оптимизации выражений), они используют техники адаптивности во время выполнения, такие как динамическая смена ядер вычислений в зависимости от характеристик данных. Аналогично, операторы плана в ClickHouse могут создавать другие операторы во время выполнения, в первую очередь для переключения на внешние операторы агрегации или соединения, основываясь на потреблении памяти запроса. В статье о Photon отмечается, что дизайны генерирования кода [38, 41, 53] труднее разрабатывать и отлаживать, чем интерпретируемые векторизированные дизайны [11]. (экспериментальная) поддержка генерации кода в Velox создает и связывает общую библиотеку, созданную из сгенерированного во время выполнения кода C++, в то время как ClickHouse взаимодействует напрямую с API компиляции LLVM по запросу.
DuckDB [67] также предназначен для встраивания в процесс-хост, но дополнительно предоставляет оптимизацию запросов и транзакции. Он был разработан для OLAP запросов, смешанных с случайными OLTP операциями. Соответственно, DuckDB выбрал формат хранения DataBlocks [43], который использует легковесные методы сжатия, такие как словари с сохранением порядка или опора [2], чтобы достичь хорошей производительности в гибридных нагрузках. В отличие от этого, ClickHouse оптимизирован для использования в режимах только добавления, т.е. без обновлений или с редкими удалениями. Блоки сжимаются с использованием тяжелых техник, таких как LZ4, предполагая, что пользователи активно используют обрезку данных для ускорения частых запросов и что затраты на ввода-вывод превышают затраты на декомпрессию для оставшихся запросов. DuckDB также предоставляет сериализуемые транзакции на основе схемы MVCC Hyper [55], в то время как ClickHouse предлагает только изолированность снимков.
8 ЗАКЛЮЧЕНИЕ И ПЕРСПЕКТИВЫ
Мы представили архитектуру ClickHouse, открытой высокопроизводительной OLAP базы данных. С оптимизированным для записи слоем хранения и современным векторизованным движком выполнения запросов в своей основе, ClickHouse позволяет проводить аналитику в реальном времени над пета-байтными наборами данных с высокой скоростью приема. Объединяя и преобразуя данные асинхронно в фоновом режиме, ClickHouse эффективно разделяет обслуживание данных и параллельные вставки. Его слой хранения позволяет агрессивно обрезать данные с использованием разреженных первичных индексов, индексов пропуска и ^^проекционных^^ таблиц. Мы описали реализацию ClickHouse обновлений и удалений, идемпотентных вставок и репликации данных между узлами для высокой доступности. Уровень обработки запросов оптимизирует запросы с использованием множества техник и параллелизует выполнение по всем ресурсам сервера и ^^кластера^^. Интеграционные движки таблиц и функции предоставляют удобный способ взаимодействия с другими системами управления данными и форматами данных. Через бенчмарки мы показываем, что ClickHouse находится среди самых быстрых аналитических баз данных на рынке, и мы показали значительные улучшения производительности типичных запросов в реальных развертываниях ClickHouse на протяжении многих лет.
Все функции и улучшения, запланированные на 2024 год, можно найти на публичной дорожной карте [18]. Запланированные улучшения включают поддержку пользовательских транзакций, PromQL [69] как альтернативного языка запросов, новый тип данных для полуструктурированных данных (например, JSON), лучшие оптимизации на уровне плана для соединений, а также реализацию легковесных обновлений для дополнения легковесных удалений.
БЛАГОДАРНОСТИ
Согласно версии 24.6, запрос SELECT * FROM system.contributors возвращает 1994 человека, которые внесли свой вклад в ClickHouse. Мы хотели бы поблагодарить всю инженерную команду ClickHouse Inc. и потрясающее сообщество с открытым исходным кодом ClickHouse за их упорный труд и преданность делу совместной разработки этой базы данных.
REFERENCES
- [1] Даниэль Абади, Петер Бонч, Ставрос Харизопулос, Стратос Идреяос и Самуэль Мэдден. 2013. Проектирование и реализация современных столбцовых систем баз данных. https://doi.org/10.1561/9781601987556
- [2] Даниэль Абади, Самуэль Мэдден и Мигель Феррейра. 2006. Интеграция сжатия и выполнения в столбцовых системах баз данных. В Материалах 2006 ACM SIGMOD Международной конференции по управлению данными (SIGMOD '06). 671–682. https://doi.org/10.1145/1142473.1142548
- [3] Анастасия Аиламаки, Дэвид Дж. ДеВитт, Марк Д. Хилл и Мариос Скуонакис. 2001. Ткачение отношений для кэширования. В Материалах 27-й Международной конференции по очень большим базам данных (VLDB '01). Morgan Kaufmann Publishers Inc., Сан-Франциско, CA, США, 169–180.
- [4] Никос Арменадзоглу, Санудж Басу, Нага Бханури, Мэньчуй Cai, Нареш Чайни, Кирен Чинта, Венкатраман Говиндараджу, Тодд Дж. Грин, Мониш Гупта, Себастьян Хиллиг, Эрик Хотингер, Ян Лешинский, Цзиньтянь Лян, Майкл МакКриди, Фабиан Нагель, Иппократис Пандис, Панос Парчас, Рахул Патхак, Орестис Полихрониу, Фойзур Рахман, Гаурав Саксена, Гокул Саундарараджан, Сирира М Subramanian и Даг Терри. 2022. Amazon Redshift Революция. В Материалах 2022 International Conference on Management of Data (Филадельфия, PA, США) (SIGMOD '22). Ассоциация вычислительной техники, Нью-Йорк, NY, США, 2205–2217. https://doi.org/10.1145/3514221.3526045
- [5] Александр Бехм, Шоумик Палькар, Уткарш Агарвал, Тимоти Армстронг, Дэвид Кэшман, Анкур Дейв, Тодд Гринстин, Шант Ховсепиан, Райан Джонсон, Арвинд Сай Кришнан, Пол Левентис, Ала Лужчак, Прашант Менон, Мостафе Мокхтар, Джин Панг, Самир Паранджпье, Грег Рахн, Барт Самвель, Том ван Буссель, Герман ван Ховел, Мэриан Сюэ, Рейнольд Ксин и Матея Захария. 2022. Photon: Быстрый движок запросов для Lakehouse систем (SIGMOD '22). Ассоциация вычислительной техники, Нью-Йорк, NY, США, 2326–2339. https://doi.org/10.1145/3514221. 3526054
- [6] Филип А. Бернштейн и Натан Гудман. 1981. Управление параллелизмом в распределенных системах баз данных. ACM Computing Survey 13, 2 (1981), 185–221. https://doi.org/10.1145/356842.356846
- [7] Спирос Бланас, Инань Ли и Джигнеш М. Пател. 2011. Проектирование и оценка алгоритмов хеш-соединения для многопроцессорных ЦПУ. В Материалах 2011 ACM SIGMOD Международной конференции по управлению данными (Афины, Греция) (SIGMOD '11). Ассоциация вычислительной техники, Нью-Йорк, NY, США, 37–48. https://doi.org/10.1145/1989323.1989328
- [8] Даниэль Гомес Бланко. 2023. Практическая OpenTelemetry. Springer Nature.
- [9] Бёртон Х. Блум. 1970. Пространственные/временные компромиссы в хеш-кодировании с допустимыми ошибками. Commun. ACM 13, 7 (1970), 422–426. https://doi.org/10.1145/362686. 362692
- [10] Петер Бонч, Томас Нойманн и Орри Эрлинг. 2014. TPC-H Анализ: Скрытые сообщения и уроки, извлеченные из значимого бенчмарка. В Характеризация производительности и бенчмаркинг. 61–76. https://doi.org/10.1007/978-3-319- 04936-6_5
- [11] Петер Бонч, Марчин Зуковски и Нiels Нэс. 2005. MonetDB/X100: Гиперпередача выполнения запросов. В CIDR.
- [12] Мартин Буртшер и Парудж Ратанаорабхан. 2007. Высокопроизводительное сжатие данных с плавающей запятой двойной точности. В Конференции по сжатию данных (DCC). 293–302. https://doi.org/10.1109/DCC.2007.44
- [13] Джефф Карпентер и Эбен Хьюитт. 2016. Cassandra: Окончательное руководство (2-е изд.). O'Reilly Media, Inc.
- [14] Бернадет Шаррон-Бост, Фернандо Педоне и Андре Шипер (Ред.). 2010. Репликация: теория и практика. Springer-Verlag.
- [15] chDB. 2024. chDB - встроенный OLAP SQL движок. Получено 2024-06-20 из https://github.com/chdb-io/chdb
- [16] ClickHouse. 2024. ClickBench: бенчмарк для аналитических баз данных. Получено 2024-06-20 из https://github.com/ClickHouse/ClickBench
- [17] ClickHouse. 2024. ClickBench: Сравнительные измерения. Получено 2024-06-20 из https://benchmark.clickhouse.com
- [18] ClickHouse. 2024. Дорожная карта ClickHouse 2024 (GitHub). Получено 2024-06-20 из https://github.com/ClickHouse/ClickHouse/issues/58392
- [19] ClickHouse. 2024. Результаты бенчмарка версий ClickHouse. Получено 2024-06-20 из https://benchmark.clickhouse.com/versions/
- [20] Andrew Crotty. 2022. MgBench. Получено 2024-06-20 из https://github.com/ andrewcrotty/mgbench
- [22] Бенуа Дажевиль, Тьерри Крюан, Марчин Зуковски, Вадим Антонов, Артин Аванес, Джон Бок, Джонатан Клейбауг, Даниил Енговатова, Мартин Хентшель, Цзяньшэн Хуан, Элизабет Ли, Ашиш Мотивала, Абдул Q. Мунир, Стивен Пелли, Петер Повинец, Грег Рахн, Спиридон Триантафиллис и Филипп Унтербруннер. 2016. Хранилище данных Snowfake Elastic. В Материалах 2016 International Conference on Management of Data (Сан-Франциско, Калифорния, США) (SIGMOD '16). Ассоциация вычислительной техники, Нью-Йорк, NY, США, 215–226. https: //doi.org/10.1145/2882903.2903741
- [23] Патрик Дамм, Аннетт Унгетхюм, Джулиана Хилдебрандт, Дирк Хабих и Вольфганг Лехнер. 2019. От комплексного экспериментального опроса до стратегии выбора на основе затрат для легковесных алгоритмов сжатия целых чисел. ACM Trans. Database Syst. 44, 3, Статья 9 (2019), 46 страниц. https://doi.org/10.1145/3323991
- [24] Филипп Доббелаер и Кюмарс Шейк Эсмаили. 2017. Kafka против RabbitMQ: сравнительное исследование двух промышленных эталонных реализаций Publish/Subscribe: статья для индустрии (DEBS '17). Ассоциация вычислительной техники, Нью-Йорк, NY, США, 227–238. https://doi.org/10.1145/3093742.3093908
- [25] Документация LLVM. 2024. Автовекторизация в LLVM. Получено 2024-06-20 из https://llvm.org/docs/Vectorizers.html
- [26] Сийинг Дунг, Эндрю Крычка, Янцин Цзин и Майкл Штумм. 2021. RocksDB: Эволюция приоритетов разработки в системе хранения ключ-значение, обслуживающей крупномасштабные приложения. ACM Transactions on Storage 17, 4, Статья 26 (2021), 32 страницы. https://doi.org/10.1145/3483840
- [27] Маркус Дреселер, Мартин Бойсье, Тилльман Рабл и Маттиас Уфаар. 2020. Количественное измерение узких мест TPC-H и их оптимизации. Proc. VLDB Endow. 13, 8 (2020), 1206–1220. https://doi.org/10.14778/3389133.3389138
- [28] Тед Даннинг. 2021. t-digest: эффективные оценки распределений. Software Impacts 7 (2021). https://doi.org/10.1016/j.simpa.2020.100049
- [29] Мартин Фауст, Мартин Бойсье, Марвин Келлер, Дэвид Швальб, Хольгер Бишоф, Катрин Эйзенрайх, Франц Фёрбер и Хассо Платтнер. 2016. Сокращение отпечатков и обеспечение уникальности с помощью хеш-индексов в SAP HANA. В Приложениях баз данных и экспертных систем. 137–151. https://doi.org/10.1007/978-3-319-44406- 2_11
- [30] Филипп Флажо и Эрик Фюси, Оливье Гандуэ и Фредерик Менье. 2007. HyperLogLog: анализ алгоритма оценки почти оптимальной кардинальности. В AofA: Анализ алгоритмов, Том. DMTCS Proceedings том AH, 2007 Конференция по анализу алгоритмов (AofA 07). Дискретная математика и теоретическая информатика, 137–156. https://doi.org/10.46298/dmtcs.3545
- [31] Гектор Гарсия-Молина, Джефри Д. Ульман и Дженнифер Уидом. 2009. Системы баз данных - Полная книга (2-е изд.).
- [32] Паван Гойал, Харрик М. Вин и Хайчен Чен. 1996. Честный очередь по времени начала: алгоритм планирования для интегрированных сервисов пакетной передачи. 26, 4 (1996), 157–168. https://doi.org/10.1145/248157.248171
- [33] Гетц Грейф. 1993. Техники оценки запросов для больших баз данных. ACM Comput. Surv. 25, 2 (1993), 73–169. https://doi.org/10.1145/152610.152611
- [34] Жан-Франсуа Им, Кишор Гопалакришна, Суббу Субраманиам, Маянк Шривастава, Адваит Тумбде, Сяотянь Цзянь, Дженнифер Дай, Сеунгхьюн Ли, Неха Паварар, Цзялианг Ли и Рави Арингунам. 2018. Pinot: Реальный OLAP для 530 миллионов пользователей. В Материалах 2018 Международной конференции по управлению данными (Хьюстон, Техас, США) (SIGMOD '18). Ассоциация вычислительной техники, Нью-Йорк, NY, США, 583–594. https://doi.org/10.1145/3183713.3190661
- [35] ISO/IEC 9075-9:2001 2001. Информационные технологии — Язык базы данных — SQL — Часть 9: Управление внешними данными (SQL/MED). Стандарт. Международная организация по стандартизации.
- [36] Парас Джейн, Петер Крафт, Конор Пауэр, Татагата Дас, Ион Стойка и Матея Захария. 2023. Анализ и сравнение систем хранения Lakehouse. CIDR.
- [37] Проект Jupyter. 2024. Jupyter Notebooks. Получено 2024-06-20 из https: //jupyter.org/
- [38] Тимо Керстен, Виктор Лейс, Альфонс Кемпер, Томас Нойманн, Эндрю Павло и Петер Бонч. 2018. Все, что вы всегда хотели знать о компилированных и векторных запросах, но боялись спросить. Proc. VLDB Endow. 11, 13 (сентябрь 2018), 2209–2222. https://doi.org/10.14778/3275366.3284966
- [39] Чангкю Ким, Джатин Чхугани, Нададур Сатиш, Эрик Седлар, Антони Д. Нгуен, Тим Келдевей, Виктор В. Ли, Скотт А. Брандт и Прадип Дубей. 2010. FAST: Быстрая архитектурно-ориентированная операция поиска дерева на современных ЦПУ и ГПУ. В Материалах 2010 ACM SIGMOD Международной конференции по управлению данными (Индианаполис, Индиана, США) (SIGMOD '10). Ассоциация вычислительной техники, Нью-Йорк, NY, США, 339–350. https://doi.org/10.1145/1807167.1807206
- [40] Дональд Е. Кнут. 1973. Искусство компьютерного программирования, Том III: Сортировка и поиск. Addison-Wesley.
- [41] Андре Кохн, Виктор Лейс и Томас Нойманн. 2018. Адаптивное выполнение скомпилированных запросов. В 2018 IEEE 34-й Международной конференции по инженерии данных (ICDE). 197–208. https://doi.org/10.1109/ICDE.2018.00027
- [42] Эндрю Лэмб, Мэтт Фуллер, Рамакиришна Варадраjan, Нга Тран, Бен Вандивер, Лирик Доши и Чак Бир. 2012. База данных Vertica: C-Store через 7 лет. Proc. VLDB Endow. 5, 12 (авг 2012), 1790–1801. https://doi.org/10. 14778/2367502.2367518
- [43] Харальд Ланг, Тобиас Мюльбауэр, Флориан Функе, Петер А. Бонч, Томас Нойманн и Альфонс Кемпер. 2016. Блоки данных: Гибридный OLTP и OLAP на сжатом хранилище с использованием как векторизации, так и компиляции. В Материалах 2016 Международной конференции по управлению данными (Сан-Франциско, Калифорния, США) (SIGMOD '16). Ассоциация вычислительной техники, Нью-Йорк, NY, США, 311–326. https://doi.org/10.1145/2882903.2882925
- [44] Виктор Лейс, Петер Бонч, Альфонс Кемпер и Томас Нойман. 2014. Morseldriven параллелизм: фреймворк оценки запросов, учитывающий NUMA для эпохи многоядерных систем. В Материалах 2014 ACM SIGMOD Международной конференции по управлению данными (Сноубёрд, Юта, США) (SIGMOD '14). Ассоциация вычислительной техники, Нью-Йорк, NY, США, 743–754. https://doi.org/10.1145/2588555. 2610507
- [45] Виктор Лейс, Альфонс Кемпер и Томас Нойман. 2013. Адаптивное дерево Рэдикс: ARTful индексирование для баз данных в оперативной памяти. В 2013 IEEE 29-й Международной конференции по инженерии данных (ICDE). 38–49. https://doi.org/10.1109/ICDE. 2013.6544812
- [46] Чунвэй Лю, Анна Павленко, Маттео Интерланди и Брендон Хейнс. 2023. Глубокий анализ общих открытых форматов для аналитических СУБД. 16, 11 (июль 2023), 3044–3056. https://doi.org/10.14778/3611479.3611507
- [47] Чжэнхуа Лю, Хуан Хуберт Чжан, Ганг Сян, Ганг Гуо, Хаозу Ван, Цзинбао Чен, Асим Правин, Ю Янг, Сяомин Гао, Александра Ван, Вэнь Линь, Ашвин Агравал, Цзюньфэн Ян, Хао У, Сяолианг Ли, Фэн Гуо, Цзянь У, Джесси Чжан и Венкатеш Рагаван. 2021. Greenplum: Гибридная база данных для транзакционных и аналитических нагрузок (SIGMOD '21). Ассоциация вычислительной техники, Нью-Йорк, NY, США, 2530–2542. https: //doi.org/10.1145/3448016.3457562
- [48] Роджер МакНикол и Блейн Фрэнч. 2004. Sybase IQ Multiplex - Разработан для аналитики. В Материалах Тридцатой Международной конференции по очень большим базам данных - Том 30 (Торонто, Канада) (VLDB '04). VLDB Endowment, 1227–1230.
- [49] Сергей Мельник, Андрей Губарев, Цзинь Цзинь Лонг, Геофри Ромер, Шива Шивакумар, Мэтт Толтон, Тео Василакис, Хосейн Ахмади, Дэн Делори, Слава Мин, Моша Пасумански и Джефф Шут. 2020. Dremel: Десятилетие интерактивного SQL анализа в веб-масштабе. Proc. VLDB Endow. 13, 12 (авг 2020), 3461–3472. https://doi.org/10.14778/3415478.3415568
- [50] Microsoft. 2024. Язык запросов Kusto. Получено 2024-06-20 из https: //github.com/microsoft/Kusto-Query-Language
- [51] Гвидо Мёркотте. 1998. Малые материализованные агрегаты: легкая индексная структура для хранилищ данных. В Материалах 24-й Международной конференции по очень большим базам данных (VLDB '98). 476–487.
- [52] Джалал Мостафа, Сара Вехби, Сурен Чилингарян и Андреас Копманн. 2022. SciTS: Бенчмарк для баз данных временных рядов в научных экспериментах и промышленном Интернете вещей. В Материалах 34-й Международной конференции по научному и статистическому управлению базами данных (SSDBM '22). Статья 12. https: //doi.org/10.1145/3538712.3538723
- [53] Томас Нойманн. 2011. Эффективная компиляция эффективных планов запросов для современного оборудования. Proc. VLDB Endow. 4, 9 (июнь 2011), 539–550. https://doi.org/10.14778/ 2002938.2002940
- [54] Томас Нойманн и Майкл Дж. Фрайтаг. 2020. Umbra: Система на основе диска с производительностью в памяти. В 10-й Конференции по исследованию инновационных систем данных, CIDR 2020, Амстердам, Нидерланды, 12-15 января 2020 года, онлайн материалы. www.cidrdb.org. http://cidrdb.org/cidr2020/papers/p29-neumanncidr20.pdf
- [55] Томас Нойманн, Тобиас Мюльбауэр и Альфонс Кемпер. 2015. Быстрый сериализуемый многоверсный контроль параллелизма для систем баз данных в оперативной памяти. В Материалах 2015 ACM SIGMOD Международной конференции по управлению данными (Мельбурн, Виктория, Австралия) (SIGMOD '15). Ассоциация вычислительной техники, Нью-Йорк, NY, США, 677–689. https://doi.org/10.1145/2723372. 2749436
- [56] LevelDB на GitHub. 2024. LevelDB. Получено 2024-06-20 из https://github. com/google/leveldb
- [57] Патрик О'Нил, Элизабет О'Нил, Сюэдонг Чен и Стивен Ревилак. 2009. Бенчмарк схемы звезды и индексирование дополненной таблицы фактов. В Оценке производительности и бенчмаркинге. Springer Berlin Heidelberg, 237–252. https: //doi.org/10.1007/978-3-642-10424-4_17
- [58] Патрик Е. О'Нил, Эдвард Y. C. Ченг, Дитер Гавлик и Элизабет Дж. О'Нил. 1996. Логическая структура Merge-дерево (LSM-дерево). Acta Informatica 33 (1996), 351–385. https://doi.org/10.1007/s002360050048
- [59] Диего Онгаро и Джон Оустерхут. 2014. В поисках понятного алгоритма консенсуса. В Материалах 2014 USENIX Конференции по техническим аспектам (USENIX ATC'14). 305–320. https://doi.org/doi/10. 5555/2643634.2643666
- [60] Патрик О'Нил, Эдвард Ченг, Дитер Гавлик и Элизабет О'Нил. 1996. Логическая структура Merge-дерево (LSM-дерево). Acta Inf. 33, 4 (1996), 351–385. https: //doi.org/10.1007/s002360050048
- [61] Pandas. 2024. Pandas Dataframes. Получено 2024-06-20 из https://pandas. pydata.org/
- [62] Педро Педрейра, Орри Эрлинг, Маша Басманова, Кевин Уилфонг, Лаит Сакка, Кришна Пай, Вей Хэ и Бисвапеш Чхатопадхья. 2022. Velox: Единый движок выполнения Meta. Proc. VLDB Endow. 15, 12 (авг 2022), 3372–3384. https: //doi.org/10.14778/3554821.3554829
- [63] Туомас Пелконен, Скотт Франклин, Джастин Теллер, Пол Кавалларо, Ци Хуан, Джастин Меза и Каушик Вииарагавин. 2015. Gorilla: Быстрая, масштабируемая, in-memory база данных временных рядов. Материалы VLDB Endowment 8, 12 (2015), 1816–1827. https://doi.org/10.14778/2824032.2824078
- [64] Орестис Полихрониу, Арун Рагаван и Кеннет А. Росс. 2015. Переосмысление SIMD-векторизации для баз данных в оперативной памяти. В Материалах 2015 ACM SIGMOD Международной конференции по управлению данными (SIGMOD '15). 1493–1508. https://doi.org/10.1145/2723372.2747645
- [65] PostgreSQL. 2024. PostgreSQL - Внешние обертки данных. Получено 2024-06-20 из https://wiki.postgresql.org/wiki/Foreign_data_wrappers
- [66] Марк Раасвельдт, Педро Холанда, Тим Губнер и Ханнес Мюлейзен. 2018. Честный бенчмарк считается сложным: общие подводные камни в тестировании производительности баз данных. В Материалах Семинара по тестированию систем баз данных (Хьюстон, Техас, США) (DBTest'18). Статья 2, 6 страниц. https://doi.org/10.1145/3209950.3209955
- [67] Марк Раасвельдт и Ханнес Мюлейзен. 2019. DuckDB: Встраиваемая аналитическая база данных (SIGMOD '19). Ассоциация вычислительной техники, Нью-Йорк, NY, США, 1981–1984. https://doi.org/10.1145/3299869.3320212
- [68] Джун Рао и Кеннет А. Росс. 1999. Индексирование с учетом кэширования для поддержки принятия решений в оперативной памяти. В Материалах 25-й Международной конференции по очень большим базам данных (VLDB '99). Сан-Франциско, Калифорния, США, 78–89.
- [69] Навин С. Сабхарвал и Пиюш Кант Пандей. 2020. Работа с языком запросов Prometheus (PromQL). В Мониторинг микросервисов и контейнеризованных приложений. https://doi.org/10.1007/978-1-4842-6216-0_5
- [70] Тодд В. Шнайдер. 2022. Данные такси Нью-Йорка и автомобили для наемной работы. Получено 2024-06-20 из https://github.com/toddwschneider/nyc-taxi-data
- [71] Майк Стоунбрейкер, Даниэль Дж. Абади, Адам Бэткин, Сюэдонг Чен, Митч Черняк, Мигель Феррейра, Эдмонд Лау, Амирсон Лин, Сэм Мэдден, Элизабет О'Нил, Пат О'Нил, Алекс Расин, Нга Тран и Стэн Здоник. 2005. C-Store: Столбцовая СУБД. В Материалах 31-й Международной конференции по очень большим базам данных (VLDB '05). 553–564.
- [72] Teradata. 2024. База данных Teradata. Получено 2024-06-20 из https://www. teradata.com/resources/datasheets/teradata-database
- [73] Фредерик Трансир. 2010. Алгоритмы и структуры данных для in-memory поисковых систем текста. Диссертация на соискание степени Ph.D. https://doi.org/10.5445/IR/1000015824
- [74] Адриан Вогельсгезанг, Майкл Хаубеншильд, Ян Финіс, Альфонс Кемпер, Виктор Лейс, Тобиас Мюлблер, Томас Нойман и Мануэль Тен. 2018. Будьте реалистами: как бенчмарки не отражают реальный мир. В Материалах Семинара по тестированию систем баз данных (Хьюстон, Техас, США) (DBTest'18). Статья 1, 6 страниц. https://doi.org/10.1145/3209950.3209952
- [75] Веб-сайт LZ4. 2024. LZ4. Получено 2024-06-20 из https://lz4.org/
- [76] Веб-сайт PRQL. 2024. PRQL. Получено 2024-06-20 из https://prql-lang.org [77] Тилль Вестман, Дональд Коссмман, Свен Хелмер и Гвидо Мёркотте. 2000. Реализация и производительность сжатых баз данных. SIGMOD Rec.
- 29, 3 (сен 2000), 55–67. https://doi.org/10.1145/362084.362137 [78] Фанцзин Ян, Эрик Цшеттер, Ксавье Ляуте, Нельсон Рей, Гиан Мерлино и Дип Гангури. 2014. Druid: Хранилище данных для аналитики в реальном времени. В Материалах 2014 ACM SIGMOD Международной конференции по управлению данными (Сноубёрд, Юта, США) (SIGMOD '14). Ассоциация вычислительной техники, Нью-Йорк, NY, США, 157–168. https://doi.org/10.1145/2588555.2595631
- [79] Тяньци Чжэн, Чжибин Чжан и Сюэци Ченг. 2020. SAHA: адаптивная хеш-таблица строк для аналитических баз данных. Применяемые науки 10, 6 (2020). https: //doi.org/10.3390/app10061915
- [80] Цзиньжэнь Чжоу и Кеннет А. Росс. 2002. Реализация операций баз данных с использованием инструкций SIMD. В Материалах 2002 ACM SIGMOD Международной конференции по управлению данными (SIGMOD '02). 145–156. https://doi.org/10. 1145/564691.564709
- [81] Марчин Зуковски, Шандор Хеман, Нiels Нэс и Петер Бонч. 2006. Сжатие кэша RAM-ЦПУ суперскалярного типа. В Материалах 22-й Международной конференции по инженерии данных (ICDE '06). 59. https://doi.org/10.1109/ICDE. 2006.150
