Минимизировать и оптимизировать JOIN
ClickHouse поддерживает широкий спектр типов и алгоритмов JOIN, и производительность JOIN значительно улучшилась в последних релизах. Однако JOIN по своей природе более затратные, чем запросы к одной денормализованной таблице. Денормализация переносит вычислительные нагрузки с времени запроса на время вставки или предварительной обработки, что часто приводит к значительно более низкой задержке во время выполнения. Для аналитических запросов в реальном времени или чувствительных к задержке, денормализация настоятельно рекомендуется.
В общем, рекомендуется выполнять денормализацию, когда:
- Таблицы изменяются нечасто или когда пакетные обновления приемлемы.
- Связи не являются многие ко многим или не имеют чрезмерно высокой кардинальности.
- Запрашивается только ограниченный набор колонок, т.е. некоторые колонки могут быть исключены из денормализации.
- У вас есть возможность перенести обработку из ClickHouse в системы верхнего уровня, такие как Flink, где можно управлять обогащением в реальном времени или упрощением.
Не все данные нужно денормализовать - сосредоточьтесь на атрибутах, которые запрашиваются часто. Также рассмотрите возможность использования материализованных представлений для поэтапного вычисления агрегатов вместо дублирования целых подтаблиц. Когда обновления схемы происходят редко и задержка критична, денормализация предлагает лучший компромисс по производительности.
Для получения полного руководства по денормализации данных в ClickHouse смотрите здесь.
Когда необходимы JOIN
Когда необходимы JOIN, убедитесь, что вы используете по крайней мере версию 24.12 и предпочтительно последнюю версию, так как производительность JOIN продолжает улучшаться с каждым новым релизом. Начиная с ClickHouse 24.12, планировщик запросов теперь автоматически размещает меньшую таблицу на правой стороне JOIN для оптимальной производительности - задача, которую ранее пришлось выполнять вручную. Скоро будут доступны еще более значительные улучшения, включая более агрессивное пропускание фильтров и автоматическую переупорядочивание нескольких JOIN.
Следуйте этим лучшим практикам для улучшения производительности JOIN:
- Избегайте декартовых произведений: Если значение с левой стороны совпадает с несколькими значениями с правой стороны, JOIN вернет несколько строк - так называемое декартово произведение. Если ваш случай использования не требует всех совпадений с правой стороны, а только любое одно совпадение, вы можете использовать
ANYJOIN (например,LEFT ANY JOIN). Они быстрее и используют меньше памяти, чем обычные JOIN. - Сократите размеры JOINed таблиц: Время выполнения и потребление памяти JOIN увеличивается пропорционально размерам левой и правой таблиц. Чтобы сократить объем обрабатываемых данных с помощью JOIN, добавьте дополнительные условия фильтрации в
WHEREилиJOIN ONклаузах запроса. ClickHouse продвигает условия фильтрации как можно глубже в план запроса, обычно перед JOIN. Если фильтры не продвигаются автоматически (по любым причинам), перепишите одну сторону JOIN как подзапрос, чтобы принудительно выполнить продвижение. - Используйте прямые JOIN через словари, если это уместно: Стандартные JOIN в ClickHouse выполняются в два этапа: этап построения, который итеративно обрабатывает правую сторону для построения хеш-таблицы, за которым следует этап поиска, который итеративно обрабатывает левую сторону для поиска совпадающих партнеров JOIN через хеш-таблицы. Если правая сторона является словарем или другим движком таблиц с характеристиками ключ-значение (например, EmbeddedRocksDB или движок таблицы JOIN), тогда ClickHouse может использовать алгоритм "прямого" JOIN, который эффективно устраняет необходимость в построении хеш-таблицы, ускоряя обработку запроса. Это работает для
INNERиLEFT OUTERJOIN и предпочтительно для аналитических нагрузок в реальном времени. - Используйте сортировку таблицы для JOIN: Каждая таблица в ClickHouse сортируется по колонкам первичного ключа таблицы. Возможно использовать сортировку таблиц с помощью алгоритмов так называемого сортировочного слияния JOIN, таких как
full_sorting_mergeиpartial_merge. В отличие от стандартных алгоритмов JOIN, основанных на хеш-таблицах (см. ниже,parallel_hash,hash,grace_hash), алгоритмы сортировочного слияния JOIN сначала сортируют, а затем сливают обе таблицы. Если запрос объединяет обе таблицы по их соответствующим колонкам первичного ключа, то у сортировочного слияния есть оптимизация, которая исключает этап сортировки, экономя время обработки и накладные расходы. - Избегайте JOIN, приводящих к сбросу на диск: Промежуточные состояния JOIN (например, хеш-таблицы) могут стать настолько большими, что они больше не помещаются в основную память. В этой ситуации ClickHouse по умолчанию вернет ошибку недостатка памяти. Некоторые алгоритмы JOIN (см. ниже), например,
grace_hash,partial_mergeиfull_sorting_merge, могут сбрасывать промежуточные состояния на диск и продолжать выполнение запроса. Эти алгоритмы JOIN тем не менее следует использовать с осторожностью, так как доступ к диску может значительно замедлить обработку JOIN. Мы рекомендуем оптимизировать запрос JOIN другими способами, чтобы уменьшить размер промежуточных состояний. - Значения по умолчанию в качестве маркеров отсутствия совпадений в внешних JOIN: Левые/правые/полные внешние JOIN включают все значения из левой/правой/обеих таблиц. Если для какого-либо значения не найден партнер JOIN в другой таблице, ClickHouse заменяет партнера JOIN на специальный маркер. SQL стандарт требует, чтобы базы данных использовали NULL в качестве такого маркера. В ClickHouse это требует оборачивания столбца результата в Nullable, что создает дополнительные накладные расходы по памяти и производительности. В качестве альтернативы вы можете настроить параметр
join_use_nulls = 0и использовать значение по умолчанию типа данных столбца результата в качестве маркера.
При использовании словарей для JOIN в ClickHouse важно понимать, что словари по своей конструкции не допускают дублирующихся ключей. Во время загрузки данных любые дублирующиеся ключи тихо удаляются - сохраняется только последнее загруженное значение для данного ключа. Такое поведение делает словари идеальными для отношений один к одному или многие к одному, где нужно только последнее или авторитетное значение. Однако использование словаря для отношений один ко многим или многие ко многим (например, связывание ролей с актерами, где актер может иметь несколько ролей) приведет к тихой потере данных, так как все, кроме одной из совпадающих строк, будут отброшены. В результате словари не подходят для сценариев, требующих полной реляционной целостности при нескольких совпадениях.
Выбор правильного алгоритма JOIN
ClickHouse поддерживает несколько алгоритмов JOIN, которые делают компромисс между скоростью и памятью:
- Параллельный хеш JOIN (по умолчанию): Быстрый для малых и средних правых таблиц, которые помещаются в память.
- Прямой JOIN: Идеален при использовании словарей (или других движков таблиц с характеристиками ключ-значение) с
INNERилиLEFT ANY JOIN- самый быстрый метод для точечных запросов, так как он устраняет необходимость в построении хеш-таблицы. - Полное сортировочное слияние JOIN: Эффективно, когда обе таблицы отсортированы по ключу JOIN.
- Частичное слияние JOIN: Минимизирует использование памяти, но работает медленнее - лучше всего подходит для соединения больших таблиц с ограниченной памятью.
- Grace Hash JOIN: Гибкий и регулируемый в отношении памяти, подходит для больших наборов данных с настраиваемыми характеристиками производительности.
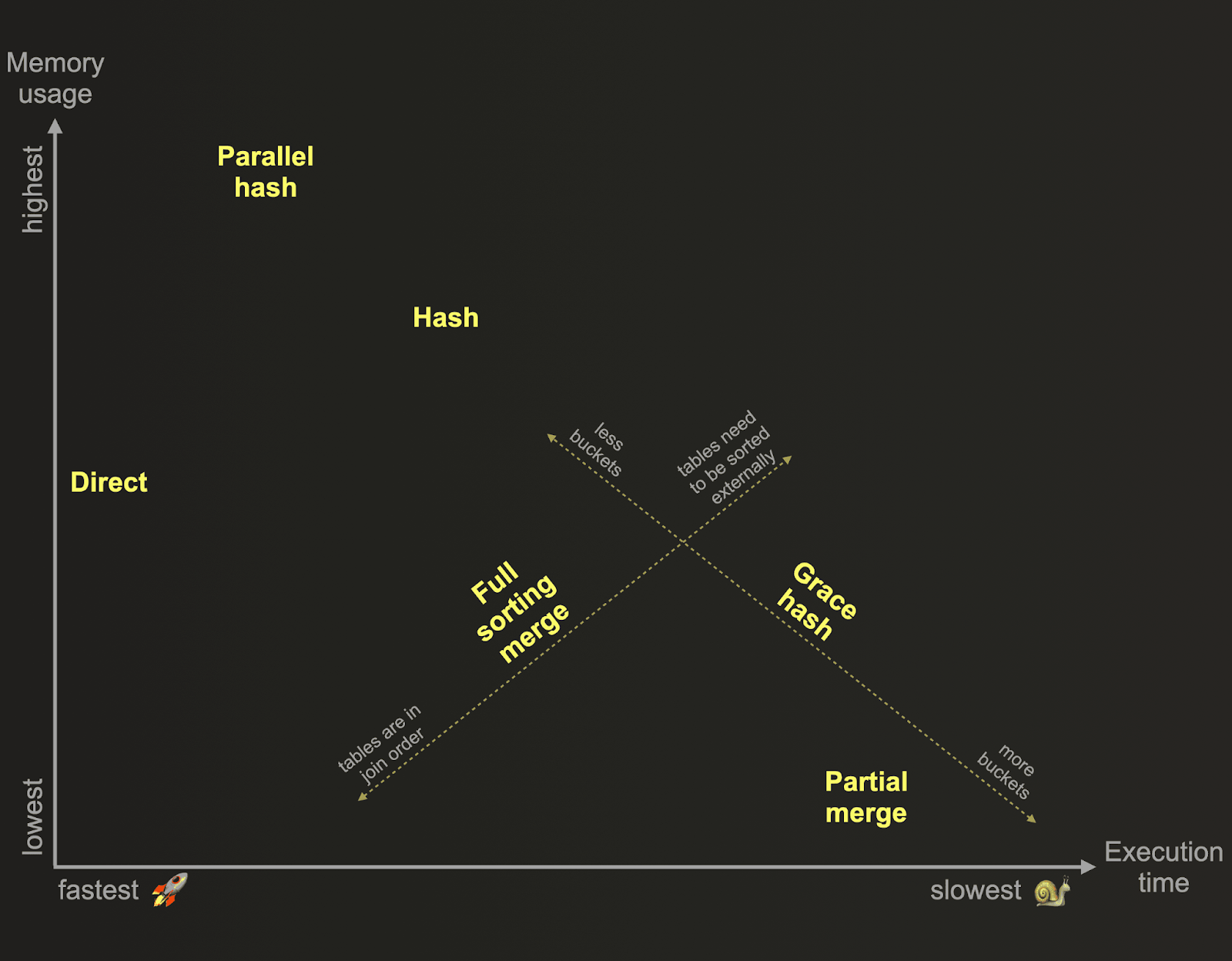
Каждый алгоритм поддерживает различные типы JOIN. Полный список поддерживаемых типов JOIN для каждого алгоритма можно найти здесь.
Вы можете позволить ClickHouse выбрать лучший алгоритм, установив join_algorithm = 'auto' (по умолчанию), или явно управлять им в зависимости от вашей рабочей нагрузки. Если вам нужно выбрать алгоритм JOIN для оптимизации производительности или накладных расходов по памяти, мы рекомендуем это руководство.
Для оптимальной производительности:
- Минимизируйте JOIN для высокопроизводительных нагрузок.
- Избегайте более 3–4 JOIN за запрос.
- Проведите бенчмаркинг различных алгоритмов на реальных данных - производительность варьируется в зависимости от распределения ключей JOIN и размера данных.
Для получения дополнительной информации о стратегиях оптимизации JOIN, алгоритмах JOIN и том, как их настроить, обратитесь к документации ClickHouse и этой серии блогов.
