Сравнение ClickHouse Cloud и BigQuery
Организация ресурсов
Способ организации ресурсов в ClickHouse Cloud схож с иерархией ресурсов BigQuery. Мы описываем конкретные различия ниже на основе следующей диаграммы, показывающей иерархию ресурсов ClickHouse Cloud:
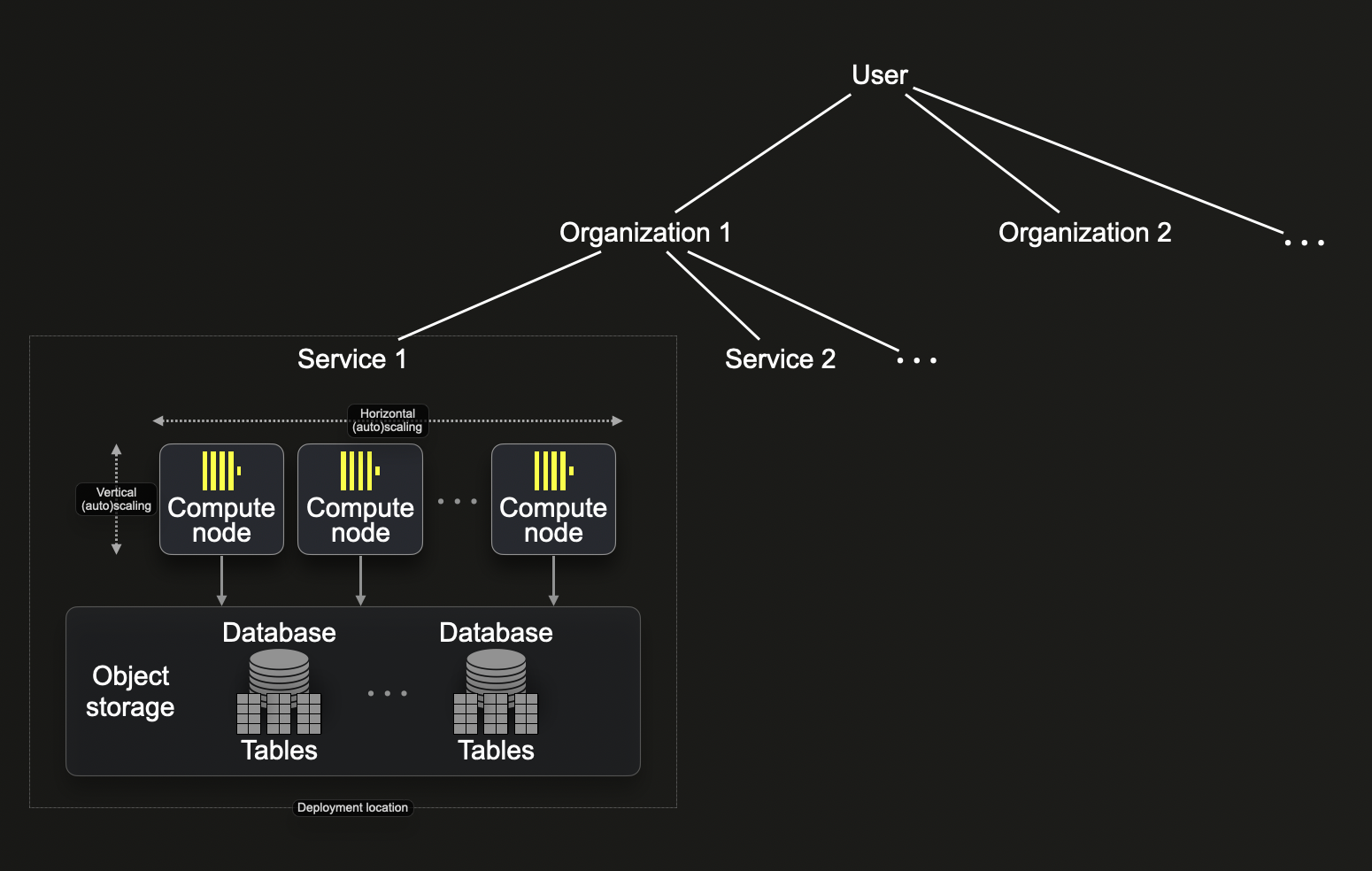
Организации
Подобно BigQuery, организации являются корневыми узлами в иерархии ресурсов ClickHouse Cloud. Первый пользователь, которого вы настраиваете в своей учетной записи ClickHouse Cloud, автоматически назначается в организацию, принадлежащую этому пользователю. Пользователь может приглашать других пользователей в организацию.
Проекты BigQuery против служб ClickHouse Cloud
Внутри организаций вы можете создавать службы, которые в некоторой степени эквивалентны проектам BigQuery, поскольку хранимые данные в ClickHouse Cloud ассоциированы со службой. В ClickHouse Cloud доступно несколько типов служб. Каждая служба ClickHouse Cloud развертывается в конкретном регионе и включает:
- Группу вычислительных узлов (в настоящее время 2 узла для службы уровня разработки и 3 для службы уровня производства). Для этих узлов ClickHouse Cloud поддерживает вертикальное и горизонтальное масштабирование, как вручную, так и автоматически.
- Папку объектного хранения, где служба хранит все данные.
- Endpoint (или несколько endpoint, созданных через консоль UI ClickHouse Cloud) - URL службы, который вы используете для подключения к службе (например,
https://dv2fzne24g.us-east-1.aws.clickhouse.cloud:8443)
Наборы данных BigQuery против баз данных ClickHouse Cloud
ClickHouse логически группирует таблицы в базы данных. Подобно наборам данных BigQuery, базы данных ClickHouse являются логическими контейнерами, которые организуют и контролируют доступ к данным таблиц.
Папки BigQuery
В ClickHouse Cloud в данный момент отсутствует концепция, эквивалентная папкам BigQuery.
Резервирование слотов и квоты BigQuery
Как и резервации слотов в BigQuery, вы можете настраивать вертикальное и горизонтальное автоматическое масштабирование в ClickHouse Cloud. Для вертикального автоматического масштабирования вы можете установить минимум и максимум для объема памяти и ядер CPU вычислительных узлов службы. Служба будет масштабироваться по мере необходимости в этих пределах. Эти настройки также доступны во время начального процесса создания службы. Каждый вычислительный узел в службе имеет одинаковый размер. Вы можете изменить количество вычислительных узлов в службе с помощью горизонтального масштабирования.
Более того, подобно квотам BigQuery, ClickHouse Cloud предлагает управление параллельностью, лимиты использования памяти и планирование I/O, позволяя пользователям изолировать запросы в классы нагрузки. Устанавливая лимиты на общие ресурсы (ядра CPU, DRAM, ввод-вывод диска и сети) для конкретных классов нагрузки, он гарантирует, что эти запросы не влияют на другие критически важные бизнес-запросы. Управление параллельностью предотвращает переподписку потоков в сценариях с высоким количеством параллельных запросов.
ClickHouse отслеживает размеры байтов выделения памяти на уровне сервера, пользователя и запроса, что позволяет гибко устанавливать лимиты использования памяти. Переполнение памяти позволяет запросам использовать дополнительную свободную память сверх гарантированной памяти, обеспечивая при этом лимиты памяти для других запросов. Кроме того, использование памяти для агрегации, сортировки и JOIN-слов можно ограничить, позволяя использовать внешние алгоритмы, когда лимит памяти превышен.
Наконец, планирование I/O позволяет пользователям ограничивать локальные и удаленные доступы к дискам для классов нагрузки на основе максимальной пропускной способности, активных запросов и политики.
Разрешения
ClickHouse Cloud контролирует доступ пользователей в двух местах: через консоль облака и через базу данных. Доступ к консоли управляется через пользовательский интерфейс clickhouse.cloud. Доступ к базе данных управляется через учетные записи пользователей баз данных и роли. Кроме того, пользователям консоли могут быть назначены роли в рамках базы данных, которые позволяют пользователю консоли взаимодействовать с базой данных через нашу SQL консоль.
Типы данных
ClickHouse предлагает более детальную точность относительно чисел. Например, BigQuery предлагает числовые типы INT64, NUMERIC, BIGNUMERIC и FLOAT64. В отличие от этого, ClickHouse предлагает несколько типов точности для десятичных, плавающих и целых чисел. С этими типами данных пользователи ClickHouse могут оптимизировать выделение памяти и хранение, что приводит к более быстрым запросам и меньшему потреблению ресурсов. Ниже мы сопоставляем эквивалентные типы ClickHouse для каждого типа BigQuery:
При выборе среди нескольких типов ClickHouse учитывайте фактический диапазон данных и выбирайте минимально необходимый. Также рекомендуем использовать подходящие кодеки для дальнейшего сжатия.
Техники ускорения запросов
Первичные и внешние ключи и первичный индекс
В BigQuery таблицы могут иметь ограничения первичного и внешнего ключа. Обычно первичные и внешние ключи используются в реляционных базах данных для обеспечения целостности данных. Значение первичного ключа, как правило, уникально для каждой строки и не может быть NULL. Каждое значение внешнего ключа в строке должно присутствовать в столбце первичного ключа основной таблицы или быть NULL. В BigQuery эти ограничения не принудительно выполняются, но оптимизатор запросов может использовать эту информацию для улучшения оптимизации запросов.
В ClickHouse таблица также может иметь первичный ключ. Как и в BigQuery, ClickHouse не требует уникальности значений столбца первичного ключа таблицы. В отличие от BigQuery, данные таблицы в ClickHouse хранятся на диске упорядоченные по значениям столбца(ов) первичного ключа. Оптимизатор запросов использует этот порядок сортировки, чтобы предотвратить повторную сортировку, минимизировать использование памяти для соединений и включить короткое замыкание для операторов LIMIT. В отличие от BigQuery, ClickHouse автоматически создает средний (разреженный) первичный индекс на основе значений столбца первичного ключа. Этот индекс используется для ускорения всех запросов, которые содержат фильтры на столбцах первичного ключа. На данный момент ClickHouse не поддерживает ограничения внешнего ключа.
Вторичные индексы (Доступны только в ClickHouse)
Кроме первичного индекса, созданного на основе значений столбца(ов) первичного ключа таблицы, ClickHouse позволяет создавать вторичные индексы на других столбцах. ClickHouse предлагает несколько типов вторичных индексов, каждый из которых подходит для различных типов запросов:
- Индекс фильтра Блума:
- Используется для ускорения запросов с условиями равенства (например, =, IN).
- Использует вероятностные структуры данных, чтобы определить, существует ли значение в блоке данных.
- Индекс токенизированного фильтра Блума:
- Похож на индекс фильтра Блума, но используется для токенизированных строк и подходит для запросов полнотекстового поиска.
- Min-Max индекс:
- Сохраняет минимальные и максимальные значения столбца для каждой части данных.
- Помогает пропустить чтение частей данных, которые не входят в заданный диапазон.
Поисковые индексы
Аналогично поисковым индексам в BigQuery, индексы полнотекстового поиска могут быть созданы для таблиц ClickHouse на столбцах со строковыми значениями.
Векторные индексы
Совсем недавно BigQuery представил векторные индексы как предварительную функцию GA. Аналогично, ClickHouse имеет экспериментальную поддержку индексов для ускорения случаев поиска векторов.
Партиционирование
Как и в BigQuery, ClickHouse использует партиционирование таблиц для повышения производительности и управляемости больших таблиц, разделяя таблицы на более мелкие, более управляемые части, называемые партициями. Мы подробно описали партиционирование в ClickHouse здесь.
Кластеризация
С помощью кластеризации BigQuery автоматически сортирует данные таблицы на основе значений нескольких заданных столбцов и размещает их в оптимально размере блоков. Кластеризация улучшает производительность запросов, позволяя BigQuery лучше оценивать стоимость выполнения запроса. С кластеризованными столбцами запросы также исключают сканирование ненужных данных.
В ClickHouse данные автоматически кластеризуются на диске на основе столбцов первичного ключа таблицы и логически организованы в блоки, которые могут быть быстро найдены или обрезаны запросами, использующими структуру данных первичного индекса.
Материализованные представления
Как BigQuery, так и ClickHouse поддерживают материализованные представления – предвычисленные результаты на основе результата запроса трансформации для повышения производительности и эффективности.
Запросы к материализованным представлениям
Материализованные представления BigQuery могут запрашиваться напрямую или использоваться оптимизатором для обработки запросов к базовым таблицам. Если изменения в базовых таблицах могут сделать материализованное представление недействительным, данные считываются напрямую из базовых таблиц. Если изменения в базовых таблицах не делают материализованное представление недействительным, то остальные данные считываются из материализованного представления, и только изменения считываются из базовых таблиц.
В ClickHouse материализованные представления можно запрашивать только напрямую. Однако, по сравнению с BigQuery (в котором материализованные представления автоматически обновляются в течение 5 минут после изменения в базовых таблицах, но не чаще чем раз в 30 минут), материализованные представления всегда синхронизированы с базовой таблицей.
Обновление материализованных представлений
BigQuery периодически полностью обновляет материализованные представления, выполняя запрос трансформации представления к базовой таблице. Между обновлениями BigQuery комбинирует данные материализованного представления с новыми данными базовой таблицы, чтобы обеспечить последовательные результаты запросов при этом продолжая использование материализованного представления.
В ClickHouse материализованные представления обновляются инкрементально. Этот механизм инкрементного обновления обеспечивает высокую масштабируемость и низкие вычислительные затраты: инкрементально обновленные материализованные представления созданы особенно для сценариев, где базовые таблицы содержат миллиарды или триллионы строк. Вместо того, чтобы постоянно запрашивать постоянно растущую базу данных для обновления материализованного представления, ClickHouse просто вычисляет частичный результат из (только) значений новых строк базовой таблицы. Этот частичный результат инкрементально сливается с ранее рассчитанным частичным результатом в фоновом режиме. Это приводит к значительно меньшим вычислительным затратам по сравнению с повторным обновлением материализованного представления из всей базовой таблицы.
Транзакции
В отличие от ClickHouse, BigQuery поддерживает многооперационные транзакции внутри одного запроса или через несколько запросов при использовании сессий. Многооперационная транзакция позволяет вам выполнять операции мутации, такие как вставка или удаление строк в одной или нескольких таблицах, и либо зафиксировать, либо откатить изменения атомарно. Многооперационные транзакции находятся на дорожной карте ClickHouse на 2024 год.
Агрегатные функции
По сравнению с BigQuery, ClickHouse предлагает значительно больше встроенных агрегатных функций:
- BigQuery предлагает 18 агрегатных функций и 4 приближенные агрегатные функции.
- ClickHouse имеет более 150 предустановленных агрегационных функций, плюс мощные агрегирующие комбинаторы для расширения поведения предустановленных агрегатных функций. Например, вы можете применить более 150 предустановленных агрегатных функций к массивам вместо строк таблицы просто вызвав их с суффиксом -Array. С помощью суффикса -Map вы можете применить любую агрегатную функцию к картам. А с помощью суффикса -ForEach вы можете применить любую агрегатную функцию к вложенным массивам.
Источники данных и форматы файлов
По сравнению с BigQuery, ClickHouse поддерживает значительно больше форматов файлов и источников данных:
- ClickHouse имеет нативную поддержку загрузки данных в 90+ форматов файлов из практически любого источника данных.
- BigQuery поддерживает 5 форматов файлов и 19 источников данных.
Возможности SQL языка
ClickHouse предоставляет стандартный SQL с множеством расширений и улучшений, которые делают его более удобным для аналитических задач. Например, SQL ClickHouse поддерживает лямбда-функции и функции высшего порядка, поэтому вам не нужно разбирать/взрывать массивы при применении преобразований. Это является большим преимуществом по сравнению с другими системами, такими как BigQuery.
Массивы
По сравнению с 8 функциями массивов BigQuery, ClickHouse имеет более 80 встроенных функций массива для элегантного и простого моделирования и решения широкого диапазона задач.
Типичный шаблон проектирования в ClickHouse – использовать агрегатную функцию groupArray для (временного) преобразования определенных значений строк таблицы в массив. Этот массив затем может быть удобно обработан через функции массива, а результат может быть обратно преобразован в отдельные строки таблицы с помощью агрегатной функции arrayJoin.
Поскольку SQL ClickHouse поддерживает лямбда-функции высшего порядка, многие сложные операции с массивами могут быть выполнены простым вызовом одной из встроенных функций массива высшего порядка, вместо того чтобы временно преобразовывать массивы обратно в таблицы, как это часто требуется в BigQuery, например, для фильтрации или объединения массивов. В ClickHouse эти операции являются всего лишь простым вызовом функций высшего порядка arrayFilter и arrayZip соответственно.
Ниже мы приводим сопоставление операций с массивами от BigQuery к ClickHouse:
| BigQuery | ClickHouse |
|---|---|
| ARRAY_CONCAT | arrayConcat |
| ARRAY_LENGTH | length |
| ARRAY_REVERSE | arrayReverse |
| ARRAY_TO_STRING | arrayStringConcat |
| GENERATE_ARRAY | range |
Создание массива с одним элементом для каждой строки в подзапросе
BigQuery
ClickHouse
Преобразование массива в набор строк
BigQuery
UNNEST оператор
ClickHouse
ARRAY JOIN оператор
Возврат массива дат
BigQuery
GENERATE_DATE_ARRAY функция
ClickHouse
Возврат массива временных меток
BigQuery
GENERATE_TIMESTAMP_ARRAY функция
ClickHouse
Фильтрация массивов
BigQuery
Требует временного преобразования массивов обратно в таблицы через UNNEST оператор
ClickHouse
arrayFilter функция
Объединение массивов
BigQuery
Требует временного преобразования массивов обратно в таблицы через UNNEST оператор
ClickHouse
arrayZip функция
Агрегация массивов
BigQuery
Требует преобразования массивов обратно в таблицы через UNNEST оператор
ClickHouse
arraySum, arrayAvg, ... функция или любая из более чем 90 существующих имен агрегатных функций в качестве аргумента для функции arrayReduce
