Миграция данных
Это Часть 1 руководства по миграции с PostgreSQL на ClickHouse. Используя практический пример, показывается, как эффективно провести миграцию с помощью подхода репликации в реальном времени (CDC). Многие из охватываемых концепций также применимы к ручной пакетной передаче данных из PostgreSQL в ClickHouse.
Набор данных
В качестве примера набора данных для демонстрации типичной миграции из Postgres в ClickHouse мы используем набор данных Stack Overflow, описанный здесь. Он содержит каждую post, vote, user, comment и badge, которые имели место на Stack Overflow с 2008 года по апрель 2024 года. Схема PostgreSQL для этих данных показана ниже:
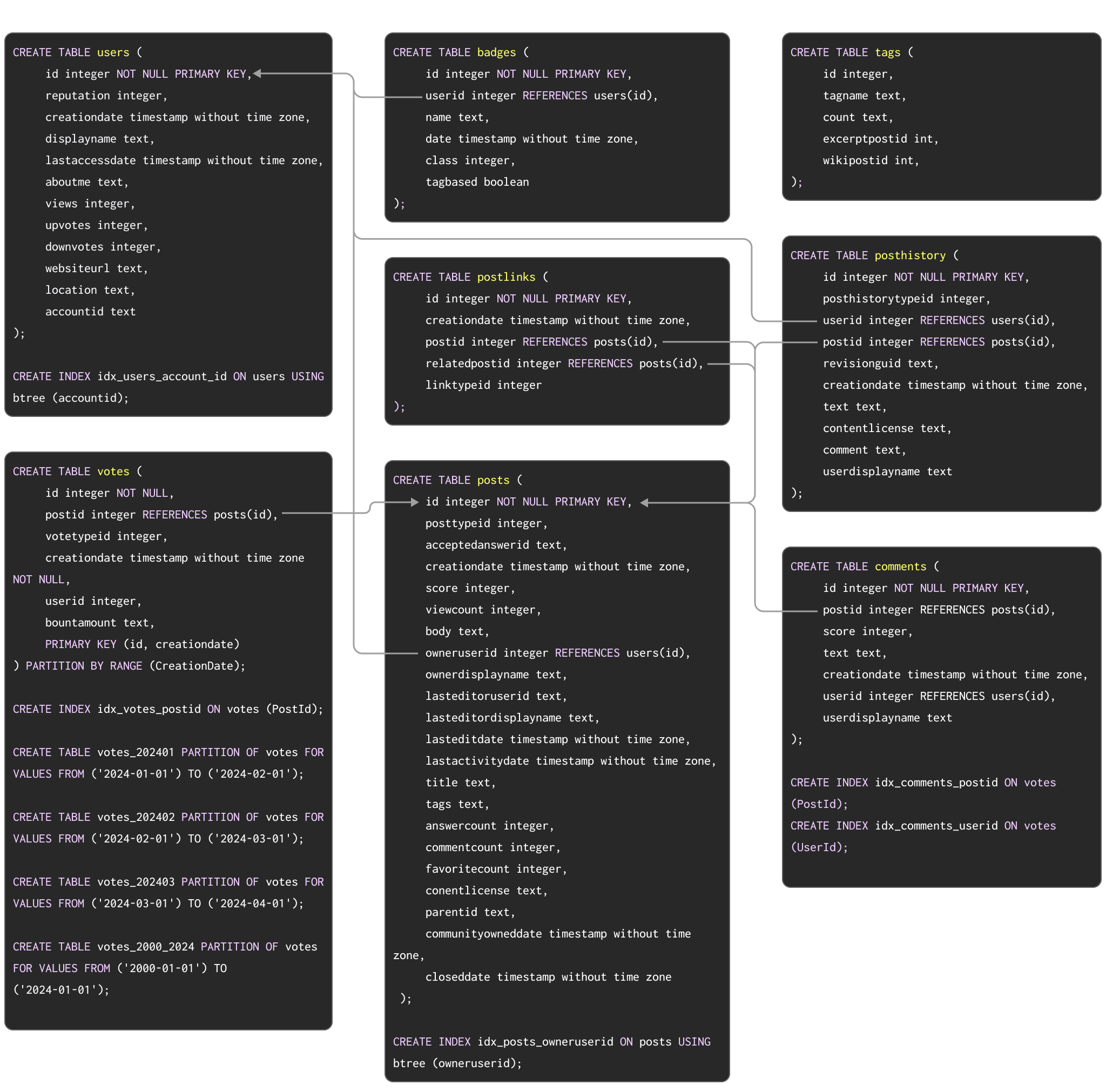
DDL-команды для создания таблиц в PostgreSQL доступны здесь.
Эта схема, хотя и не совсем оптимальная, использует ряд популярных функций PostgreSQL, включая первичные ключи, внешние ключи, партиционирование и индексы.
Мы мигрируем каждую из этих концепций на их эквиваленты в ClickHouse.
Для тех пользователей, кто хочет заполнить этот набор данных в экземпляр PostgreSQL для тестирования шагов миграции, мы предоставили данные в формате pg_dump для загрузки с DDL, а последующие команды загрузки данных показаны ниже:
Хотя для ClickHouse этот набор данных небольшой, для Postgres он значительный. Выше представлена подмножество, охватывающее первые три месяца 2024 года.
Хотя наши примеры результатов используют полный набор данных для демонстрации различий в производительности между Postgres и ClickHouse, все шаги, документированные ниже, функционально идентичны с меньшим подмножеством. Пользователям, которые хотят загрузить полный набор данных в Postgres, смотрите здесь. Из-за внешних ограничений, наложенных вышеуказанной схемой, полный набор данных для PostgreSQL содержит только те строки, которые удовлетворяют ссылочной целостности. Версия Parquet, не имеющая таких ограничений, может быть легко загружена напрямую в ClickHouse при необходимости.
Миграция данных
Репликация в реальном времени (CDC)
Обратитесь к этому руководству для настройки ClickPipes для PostgreSQL. Руководство охватывает множество различных типов исходных экземпляров Postgres.
С подходом CDC, используя ClickPipes или PeerDB, каждую таблицу в базе данных PostgreSQL автоматически реплицируют в ClickHouse.
Чтобы обработать обновления и удаления в почти реальном времени, ClickPipes сопоставляет таблицы Postgres с ClickHouse, используя движок ReplacingMergeTree, специально разработанный для обработки обновлений и удалений в ClickHouse. Вы можете найти больше информации о том, как данные реплицируются в ClickHouse с использованием ClickPipes здесь. Важно отметить, что репликация с использованием CDC создает дублированные строки в ClickHouse при репликации операций обновления или удаления. Смотрите техники с использованием модификатора FINAL для обработки этих случаев в ClickHouse.
Давайте посмотрим, как создается таблица users в ClickHouse с использованием ClickPipes.
После настройки ClickPipes начинает мигрировать все данные из PostgreSQL в ClickHouse. В зависимости от сети и размера развертываний, это должно занять всего несколько минут для набора данных Stack Overflow.
Ручная пакетная загрузка с периодическими обновлениями
С использованием ручного подхода начальная пакетная загрузка набора данных может быть выполнена с помощью:
- Табличных функций - Используя табличную функцию Postgres в ClickHouse, чтобы
SELECTданные из Postgres иINSERTих в таблицу ClickHouse. Актуально для пакетных загрузок до наборов данных объемом несколько сотен ГБ. - Экспортов - Экспорт в промежуточные форматы, такие как CSV или SQL-скрипт. Эти файлы затем могут быть загружены в ClickHouse либо с клиента через оператор
INSERT FROM INFILE, либо используя объектное хранилище и их связанные функции, т.е. s3, gcs.
При загрузке данных вручную из PostgreSQL вам сначала нужно создать таблицы в ClickHouse. Обратитесь к этой документации по моделированию данных, которая также использует набор данных Stack Overflow для оптимизации схемы таблиц в ClickHouse.
Типы данных между PostgreSQL и ClickHouse могут отличаться. Чтобы определить эквивалентные типы для каждого из столбцов таблицы, мы можем использовать команду DESCRIBE с табличной функцией Postgres. Следующая команда описывает таблицу posts в PostgreSQL, измените ее в соответствии с вашей средой:
Для обзора соответствий типов данных между PostgreSQL и ClickHouse обратитесь к документации в приложении.
Шаги для оптимизации типов для этой схемы идентичны тем, что были бы, если данные загружались из других источников, например, Parquet на S3. Применение процесса, описанного в этом альтернативном руководстве с использованием Parquet, приводит к следующей схеме:
Мы можем заполнить это с помощью простого INSERT INTO SELECT, считывая данные из PostgreSQL и вставляя их в ClickHouse:
Инкрементные загрузки могут, в свою очередь, быть запланированы. Если таблица Postgres принимает только вставки и существует инкрементный id или временная метка, пользователи могут использовать вышеописанный подход с табличной функцией для загрузки инкрементов, т.е. оператор WHERE может быть применен к SELECT. Этот подход также может быть использован для поддержки обновлений, если гарантируется, что они обновляют один и тот же столбец. Поддержка удалений, однако, потребует полной перезагрузки, что может быть сложно осуществить по мере роста таблицы.
Мы демонстрируем начальную загрузку и инкрементную загрузку, используя CreationDate (мы предполагаем, что он обновляется, если строки обновляются).
ClickHouse будет передавать простые операторы
WHERE, такие как=,!=,>,>=,<,<=, и IN на сервер PostgreSQL. Таким образом, инкрементные загрузки можно сделать более эффективными, обеспечив наличие индекса на столбцах, используемых для идентификации измененного набора.
Возможный метод обнаружения операций UPDATE при использовании репликации запросов заключается в использовании системного столбца
XMIN(идентификаторы транзакций) в качестве водяного знака - изменение в этом столбце указывает на изменение и, следовательно, может быть применено к целевой таблице. Пользователи, использующие этот подход, должны быть осведомлены о том, что значенияXMINмогут оборачиваться, и сравнения требуют полного сканирования таблицы, что делает отслеживание изменений более сложным.
