Эквивалентные концепции в ClickStack и Elastic
Elastic Stack против ClickStack
Как Elastic Stack, так и ClickStack охватывают основные роли платформы наблюдаемости, но они подходят к этим ролям с разными философиями дизайна. Эти роли включают в себя:
- UI и оповещения: инструменты для запросов к данным, создания панелей управления и управления оповещениями.
- Хранение и движок запросов: системы на стороне сервера, ответственные за хранение данных наблюдаемости и обслуживание аналитических запросов.
- Сбор данных и ETL: агенты и конвейеры, которые собирают телеметрические данные и обрабатывают их перед приемом.
В таблице ниже показано, как каждый стек сопоставляет свои компоненты с этими ролями:
| Роль | Elastic Stack | ClickStack | Комментарии |
|---|---|---|---|
| UI и оповещения | Kibana — панели мониторинга, поиск и оповещения | HyperDX — интерфейс в реальном времени, поиск и оповещения | Оба служат основным интерфейсом для пользователей, включая визуализации и управление оповещениями. HyperDX специально разработан для наблюдаемости и тесно связан с семантикой OpenTelemetry. |
| Хранение и движок запросов | Elasticsearch — хранилище JSON-документов с обратным индексом | ClickHouse — столбцовая база данных с векторным движком | Elasticsearch использует обратный индекс, оптимизированный для поиска; ClickHouse использует столбцовое хранение и SQL для быстрого анализа структурированных и полуструктурированных данных. |
| Сбор данных | Elastic Agent, Beats (например, Filebeat, Metricbeat) | OpenTelemetry Collector (edge + gateway) | Elastic поддерживает собственные шиперы и унифицированный агент, управляемый Fleet. ClickStack полагается на OpenTelemetry, позволяя сбор и обработку данных, независимые от поставщика. |
| Инструментальные SDK | Elastic APM агенты (проприетарные) | OpenTelemetry SDKs (распределяемые через ClickStack) | SDK Elastic привязаны к стеку Elastic. ClickStack строится на SDK OpenTelemetry для логов, метрик и трассировок на основных языках. |
| ETL / Обработка данных | Logstash, конвейеры приёма данных | OpenTelemetry Collector + материализованные представления ClickHouse | Elastic использует конвейеры приёма данных и Logstash для преобразования. ClickStack перемещает вычисления во время вставки через материализованные представления и процессоры коллектора OTel, которые эффективно и инкрементно преобразуют данные. |
| Философия архитектуры | Вертикально интегрированные, проприетарные агенты и форматы | Основанные на открытых стандартах, слабо связанные компоненты | Elastic строит плотно интегрированную экосистему. ClickStack подчеркивает модульность и стандарты (OpenTelemetry, SQL, объектное хранилище) для гибкости и экономии затрат. |
ClickStack подчеркивает открытые стандарты и интероперабельность, полностью основанный на OpenTelemetry от сбора до интерфейса. В отличие от этого, Elastic предоставляет плотно связанный, но более вертикально интегрированный экосистему с проприетарными агентами и форматами.
Учитывая, что Elasticsearch и ClickHouse являются основными движками, ответственными за хранение данных, обработку и выполнение запросов в своих соответствующих стеках, понимание того, как они различаются, имеет решающее значение. Эти системы лежат в основе производительности, масштабируемости и гибкости всей архитектуры наблюдаемости. В следующем разделе рассматриваются ключевые различия между Elasticsearch и ClickHouse - включая то, как они моделируют данные, обрабатывают прием, выполняют запросы и управляют хранилищем.
Elasticsearch против ClickHouse
ClickHouse и Elasticsearch организуют и запрашивают данные, используя разные обоснованные модели, но многие базовые концепции служат схожим целям. Этот раздел очерчивает ключевые эквиваленты для пользователей, знакомых с Elastic, сопоставляя их с их соответствующими компонентами в ClickHouse. Хотя терминология различается, большинство рабочих процессов наблюдаемости можно воспроизвести - часто более эффективно - в ClickStack.
Основные структурные концепции
| Elasticsearch | ClickHouse / SQL | Описание |
|---|---|---|
| Поле | Колонка | Основная единица данных, содержащая одно или несколько значений определенного типа. Поля в Elasticsearch могут хранить примитивы, а также массивы и объекты. Поля могут иметь только один тип. ClickHouse также поддерживает массивы и объекты (Tuples, Maps, Nested), а также динамические типы, такие как Variant и Dynamic, которые позволяют колонке иметь несколько типов. |
| Документ | Строка | Коллекция полей (колонок). Документы Elasticsearch по умолчанию более гибкие, с новыми полями, добавляемыми динамически на основе данных (тип выводится из данных). Строки ClickHouse имеют привязку к схеме по умолчанию, пользователям необходимо вставлять все колонки для строки или их подмножество. Тип JSON в ClickHouse поддерживает эквивалентное создание динамических колонок с полуструктурированными данными на основе вставленных данных. |
| Индекс | Таблица | Единица выполнения запроса и хранения. В обеих системах запросы выполняются против индексов или таблиц, которые хранят строки/документы. |
| Неявный | Схема (SQL) | SQL-схемы группируют таблицы в пространства имен, которые часто используются для контроля доступа. Elasticsearch и ClickHouse не имеют схем, но обе поддерживают безопасность на уровне строк и таблиц через роли и RBAC. |
| Кластер | Кластер / База данных | Кластеры Elasticsearch являются экземплярами времени выполнения, которые управляют одним или несколькими индексами. В ClickHouse базы данных организуют таблицы в логическом пространстве имен, предоставляя такую же логическую группировку, как кластер в Elasticsearch. Кластер ClickHouse представляет собой распределенный набор узлов, аналогичный Elasticsearch, но он разъединен и независим от самих данных. |
Моделирование данных и гибкость
Elasticsearch известен своей гибкостью схемы благодаря динамическим отображениям. Поля создаются по мере поступления документов, а типы выводятся автоматически - если схема не указана. ClickHouse по умолчанию более строгий — таблицы определяются с явными схемами — но предлагает гибкость через типы Dynamic, Variant и JSON. Это позволяет приём полуструктурированных данных с динамическим созданием колонок и выводом типов, аналогичным Elasticsearch. Аналогично, тип Map позволяет хранить произвольные пары ключ-значение - хотя для ключа и значения применяется один тип.
Подход ClickHouse к гибкости типов более прозрачный и контролируемый. В отличие от Elasticsearch, где конфликты типов могут вызывать ошибки приёма данных, ClickHouse позволяет смешанные типы данных в колонках Variant и поддерживает эволюцию схемы через использование типа JSON.
Если не используется JSON, схема определяется статически. Если значения не предоставляются для строки, они будут определены как Nullable (не используется в ClickStack) или вернутся к значению по умолчанию для типа, например, пустое значение для String.
Прием и преобразование
Elasticsearch использует конвейеры приёма данных с процессорами (например, enrich, rename, grok), чтобы преобразовать документы перед индексированием. В ClickHouse аналогичная функциональность достигается с помощью инкрементных материализованных представлений, которые могут фильтровать, преобразовывать или добавлять данные в поступающие данные и вставлять результаты в целевые таблицы. Также можно вставлять данные в движок таблиц Null, если вам нужно только сохранить вывод материализованного представления. Это означает, что только результаты любых материализованных представлений сохраняются, но исходные данные отбрасываются - таким образом, экономится пространство для хранения.
Для обогащения Elasticsearch поддерживает специализированные процессоры обогащения, чтобы добавить контекст к документам. В ClickHouse словарь может использоваться как во время выполнения запросов, так и во время приёма данных для обогащения строк - например, для сопоставления IP-адресов с местоположениями или применения поисков по пользовательским агентам при вставке.
Языки запросов
Elasticsearch поддерживает ряд языков запросов, включая DSL, ES|QL, EQL и KQL (по стилю Lucene), но имеет ограниченную поддержку для JOIN — доступны только левая внешняя соединения через ES|QL. ClickHouse поддерживает полный синтаксис SQL, включая все типы соединений, оконные функции, подзапросы (и коррелированные), а также CTE. Это является существенным преимуществом для пользователей, которым необходимо коррелировать данные наблюдаемости с бизнес- или инфраструктурными данными.
В ClickStack HyperDX предоставляет интерфейс поиска, совместимый с Lucene для упрощения перехода вместе с полной поддержкой SQL через бэкенд ClickHouse. Этот синтаксис сопоставим с синтаксисом строки запроса Elastic. Для точного сравнения этого синтаксиса см. "Поиск в ClickStack и Elastic".
Форматы файлов и интерфейсы
Elasticsearch поддерживает приём JSON (и ограниченный CSV). ClickHouse поддерживает более 70 форматов файлов, включая Parquet, Protobuf, Arrow, CSV и другие — как для приёма данных, так и для экспорта. Это упрощает интеграцию с внешними конвейерами и инструментами.
Обе системы предлагают REST API, но ClickHouse также предоставляет родной протокол для взаимодействия с низкой задержкой и высокой пропускной способностью. Родной интерфейс поддерживает прогресс запроса, сжатие и потоковую передачу более эффективно, чем HTTP, и является стандартом для большинства производственных систем приёма данных.
Индексирование и хранение
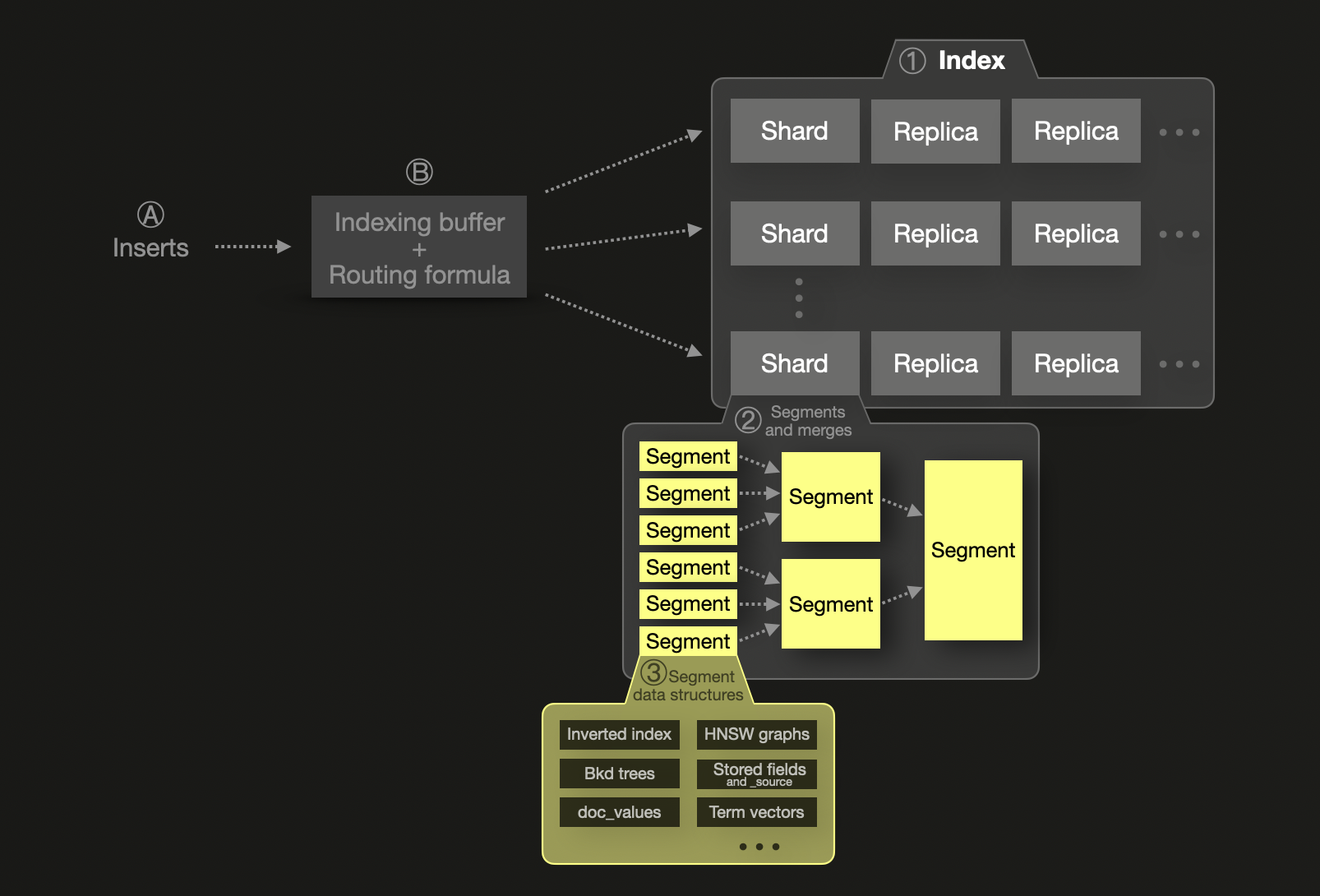
Концепция шардирования является фундаментальной для модели масштабируемости Elasticsearch. Каждый ① индекс делится на шарды, каждый из которых является физическим индексом Lucene, хранящимся в виде сегментов на диске. Шард может иметь одну или несколько физических копий, называемых репликами, для повышения отказоустойчивости. Для масштабируемости шарды и реплики могут распределяться по нескольким узлам. Один шард ② состоит из одного или нескольких неизменяемых сегментов. Сегмент является основной структурой индексирования Lucene, библиотеки Java, предоставляющей функции индексирования и поиска, на основе которой построен Elasticsearch.
Ⓐ Новые вставленные документы Ⓑ сначала попадают в буфер индексирования в памяти, который по умолчанию сбрасывается один раз в секунду. Формула маршрутизации используется для определения целевого шарда для сброшенных документов, и новый сегмент записывается для шарда на диск. Для повышения эффективности запроса и обеспечения физического удаления удаленных или обновленных документов сегменты непрерывно объединяются в фоновом режиме в более крупные сегменты, пока они не достигнут максимального размера в 5 ГБ. Однако возможно заставить объединение в более крупные сегменты.
Elasticsearch рекомендует устанавливать размер шарда на уровне около 50 ГБ или 200 миллионов документов из-за перегрузки кучи JVM и метаданных. Существует также жесткий лимит в 2 миллиарда документов на шард. Elasticsearch параллелизует запросы по шардом, но каждый шард обрабатывается с использованием единственного потока, что делает чрезмерное шардирование как затратным, так и контрпродуктивным. Это, по сути, плотно связывает шардирование с масштабированием, требуя больше шардов (и узлов) для масштабирования производительности.
Elasticsearch индексирует все поля в обратные индексы для быстрого поиска, optionally используя doc values для агрегации, сортировки и доступа к продаваемым полям. Числовые и географические поля используют Block K-D trees для поиска по геопространственным данным и числовым и временным диапазонам.
Важно, что Elasticsearch хранит полный оригинальный документ в _source (сжатый с помощью LZ4, Deflate или ZSTD), в то время как ClickHouse не хранит отдельное представление документа. Данные восстанавливаются из колонок во время выполнения запроса, что экономит место для хранения. Эта же возможность доступна для Elasticsearch с использованием Synthetic _source, с некоторыми ограничениями. Отключение _source также имеет последствия, которые не применяются к ClickHouse.
В Elasticsearch отображения индексов (эквивалентные схемам таблиц в ClickHouse) управляют типом полей и структурами данных, используемыми для этого постоянства и запросов.
ClickHouse, в отличие от этого, является столбцовой базой данных — каждая колонка хранится независимо, но всегда сортируется по первичному/упорядоченному ключу таблицы. Эта сортировка позволяет разреженным первичным индексам, которые позволяют ClickHouse эффективно пропускать данные во время выполнения запроса. Когда запросы фильтруются по полям первичного ключа, ClickHouse читает только релевантные части каждой колонки, значительно сокращая ввод-вывод диска и улучшая производительность — даже без полного индекса для каждой колонки.
ClickHouse также поддерживает индексы пропуска, которые ускоряют фильтрацию, предварительно вычисляя данные индекса для выбранных колонок. Эти индексы должны быть явно определены, но могут значительно улучшить производительность. Кроме того, ClickHouse позволяет пользователям указывать кодеки сжатия и алгоритмы сжатия для каждой колонки — чего Elasticsearch не поддерживает (его сжатие применяется только к JSON-хранению _source).
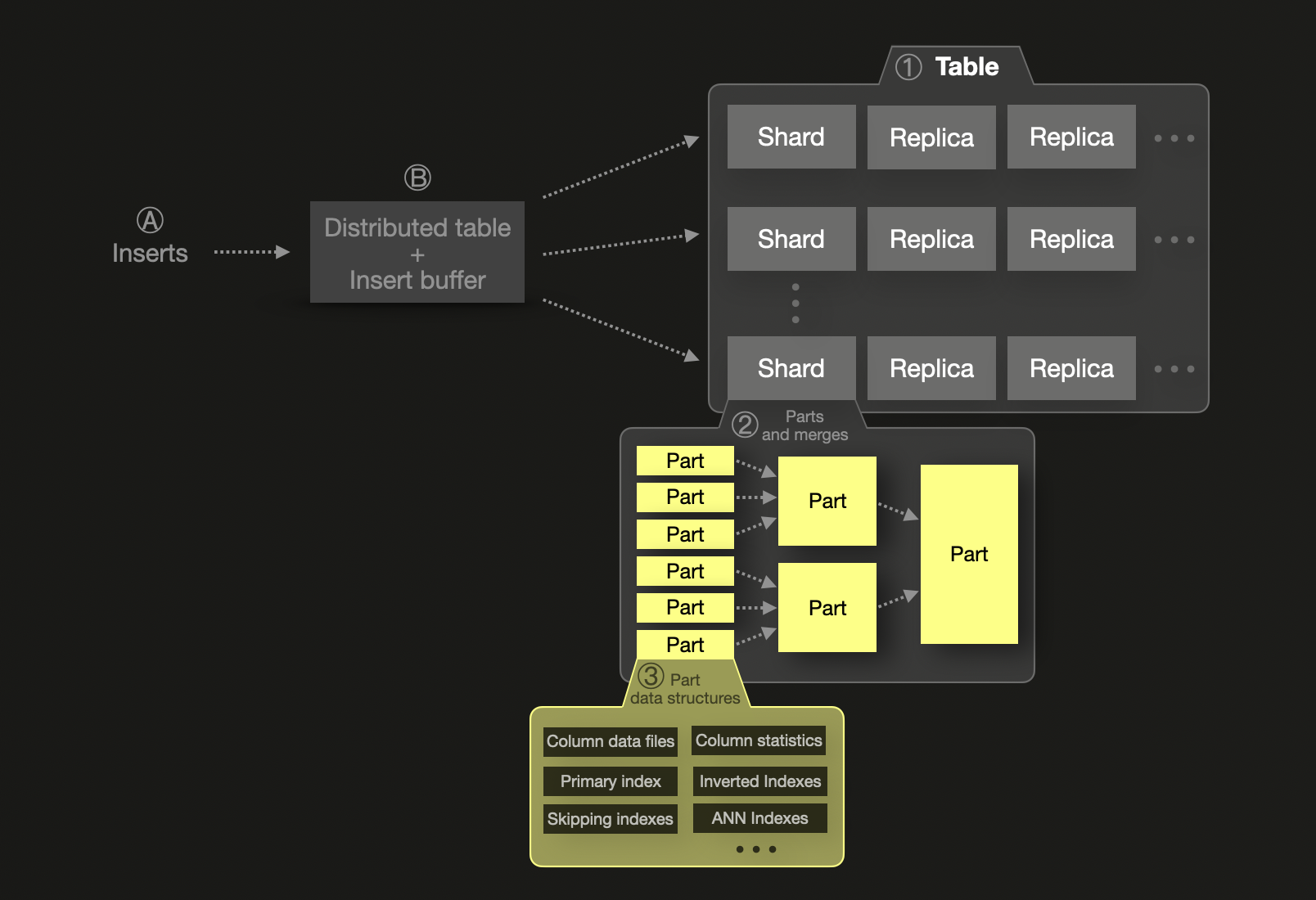
ClickHouse также поддерживает шардирование, но его модель разработана для предпочтения вертикального масштабирования. Один шард может хранить триллионы строк и продолжает работать эффективно, пока это возможно благодаря памяти, ЦП и диску. В отличие от Elasticsearch, здесь нет жесткого предела количества строк на шард. Шарды в ClickHouse являются логическими — по сути, это отдельные таблицы — и не требуют партиционирования, если объем данных не превышает емкость одного узла. Это обычно происходит из-за ограничений размера диска, шардирование ① вводится только тогда, когда необходимо горизонтальное масштабирование - уменьшая сложность и накладные расходы. В этом случае, подобно Elasticsearch, шард будет хранить подмножество данных. Данные внутри одного шарда организованы в коллекцию ② неизменяемых частей данных, содержащих ③ несколько структур данных.
Обработка внутри шардов ClickHouse полностью параллелизована, и пользователям рекомендуется масштабировать вертикально, чтобы избежать сетевых затрат, связанных с перемещением данных между узлами.
Вставки в ClickHouse по умолчанию синхронные — запись подтверждается только после коммита — но могут быть настроены для асинхронных вставок для соответствия буферизации и пакетной обработки, подобных Elastic. Если используются асинхронные вставки данных, Ⓐ вновь вставленные строки сначала попадают в Ⓑ буфер вставки в памяти, который по умолчанию сбрасывается раз в 200 миллисекунд. Если используются несколько шардов, используется распределенная таблица для маршрутизации нововставленных строк в их целевой шард. Новый объект записывается для шарда на диск.
Распределение и репликация
Хотя как Elasticsearch, так и ClickHouse используют кластеры, шарды и реплики для обеспечения масштабируемости и отказоустойчивости, их модели существенно различаются по реализации и характеристикам производительности.
Elasticsearch использует модель первичный-вторичный для репликации. Когда данные записываются в первичный шард, они синхронно копируются в одну или несколько реплик. Эти реплики сами являются полными шардом, распределенными по узлам для обеспечения избыточности. Elasticsearch подтверждает записи только после того, как все необходимые реплики подтвердят операцию — модель, которая обеспечивает почти последовательную согласованность, хотя грязные чтения из реплик возможны до полной синхронизации. Ведущий узел координирует кластер, управляя выделением шардов, здоровьем и выбором лидера.
Напротив, ClickHouse по умолчанию использует итоговую согласованность, контролируемую Keeper - легковесной альтернативой ZooKeeper. Записи могут быть отправлены на любую реплику напрямую или через распределенную таблицу, которая автоматически выбирает реплику. Репликация асинхронная - изменения пропагируются другим репликам после того, как запись подтверждена. Для более строгих гарантий ClickHouse поддерживает последовательную согласованность, когда записи подтверждаются только после того, как они были зафиксированы в репликах, хотя этот режим редко используется из-за влияния на производительность. Распределенные таблицы объединяют доступ к нескольким шадам, пересылая запросы SELECT ко всем шагам и объединяя результаты. Для операций INSERT они сбалансируют нагрузку, равномерно распределяя данные по шардов. Репликация в ClickHouse очень гибкая: любая реплика (копия шарда) может принимать записи, и все изменения асинхронно синхронизируются с другими. Эта архитектура позволяет непрерывно обслуживать запросы во время сбоев или технического обслуживания, с автоматической повторной синхронизацией - устраняя необходимость в первично-вторичном обеспечении на уровне данных.
В ClickHouse Cloud архитектура вводит модель вычислений с разделением нагрузки, где один шард поддерживается объектным хранилищем. Это заменяет традиционную высокую доступность на основе реплик, позволяя шард быть прочитанным и записанным несколькими узлами одновременно. Разделение хранения и вычислений позволяет эластичное масштабирование без явного управления репликами.
В заключение:
- Elastic: Шарды являются физическими структурами Lucene, связанными с памятью JVM. Сверхшардирование приводит к штрафам по производительности. Репликация синхронна и координируется ведущим узлом.
- ClickHouse: Шарды логические и вертикально масштабируемые, с высокой эффективностью локального выполнения. Репликация асинхронная (но может быть последовательной), а координация легковесная.
В конечном итоге ClickHouse отдает предпочтение простоте и производительности в масштабе, минимизируя необходимость в настройке шарда, при этом предлагая надежные гарантии согласованности, когда это необходимо.
Дедупликация и маршрутизация
Elasticsearch удаляет дубликаты документов по их _id, маршрутизируя их на шард соответственно. ClickHouse не хранит идентификатор строки по умолчанию, но поддерживает дедупликацию во время вставки, позволяя пользователям безопасно повторно пытаться вставки, которые не удались. Для более контроля ReplacingMergeTree и другие движки таблиц позволяют дедупликацию по конкретным колонкам.
Маршрутизация индексов в Elasticsearch гарантирует, что специфические документы всегда маршрутизируются к определенным шардом. В ClickHouse пользователи могут определить ключи шардирования или использовать Distributed таблицы, чтобы достичь аналогичной локальности данных.
Агрегации и модель выполнения
Хотя обе системы поддерживают агрегацию данных, ClickHouse предлагает значительно больше функций, включая статистические, аппроксимирующие и специализированные аналитические функции.
В случаях наблюдаемости одним из самых распространенных приложений агрегации является подсчет того, как часто происходят определенные журналы сообщений или события (и оповещение в случае, если частота необычна).
Эквивалент SQL-запроса ClickHouse SELECT count(*) FROM ... GROUP BY ... в Elasticsearch — это агрегация terms, которая является агрегацией по бакетам в Elasticsearch.
GROUP BY ClickHouse с count(*) и агрегация terms в Elasticsearch обычно эквивалентны по функциональности, но они значительно различаются по своей реализации, производительности и качеству результатов.
Эта агрегация в Elasticsearch оценивает результаты в запросах "top-N" (например, топ 10 хостов по количеству), когда запрашиваемые данные охватывают несколько шардов. Эта оценка повышает скорость, но может ухудшить точность. Пользователи могут уменьшить эту ошибку, проверяя doc_count_error_upper_bound и увеличивая параметр shard_size — с ценой увеличения использования памяти и более медленной производительности запроса.
Elasticsearch также требует установки size для всех агрегатов по бакетам — нет способа вернуть все уникальные группы без явной установки лимита. Агрегации с высокой кардинальностью рискуют достичь max_buckets ограничения или требуют разбиения с помощью составной агрегации, что часто бывает сложным и неэффективным.
ClickHouse, в отличие от этого, выполняет точные агрегации из коробки. Функции, такие как count(*), возвращают точные результаты без необходимости настройки, что делает поведение запроса проще и предсказуемее.
ClickHouse не накладывает никаких ограничений на размер. Вы можете выполнять запросы group-by без ограничений по объему данных. Если пороги памяти превышены, ClickHouse может сбрасывать результат на диск. Агрегации, которые группируют по префиксу первичного ключа, особенно эффективны, часто выполняются с минимальным использованием памяти.
Модель выполнения
Указанные различия можно объяснить различиями в моделях выполнения Elasticsearch и ClickHouse, которые применяют фундаментально разные подходы к выполнению запросов и параллелизму.
ClickHouse был разработан для максимизации эффективности на современном оборудовании. По умолчанию ClickHouse выполняет SQL-запрос с N параллельными канавками выполнения на машине с N ядрами ЦП:
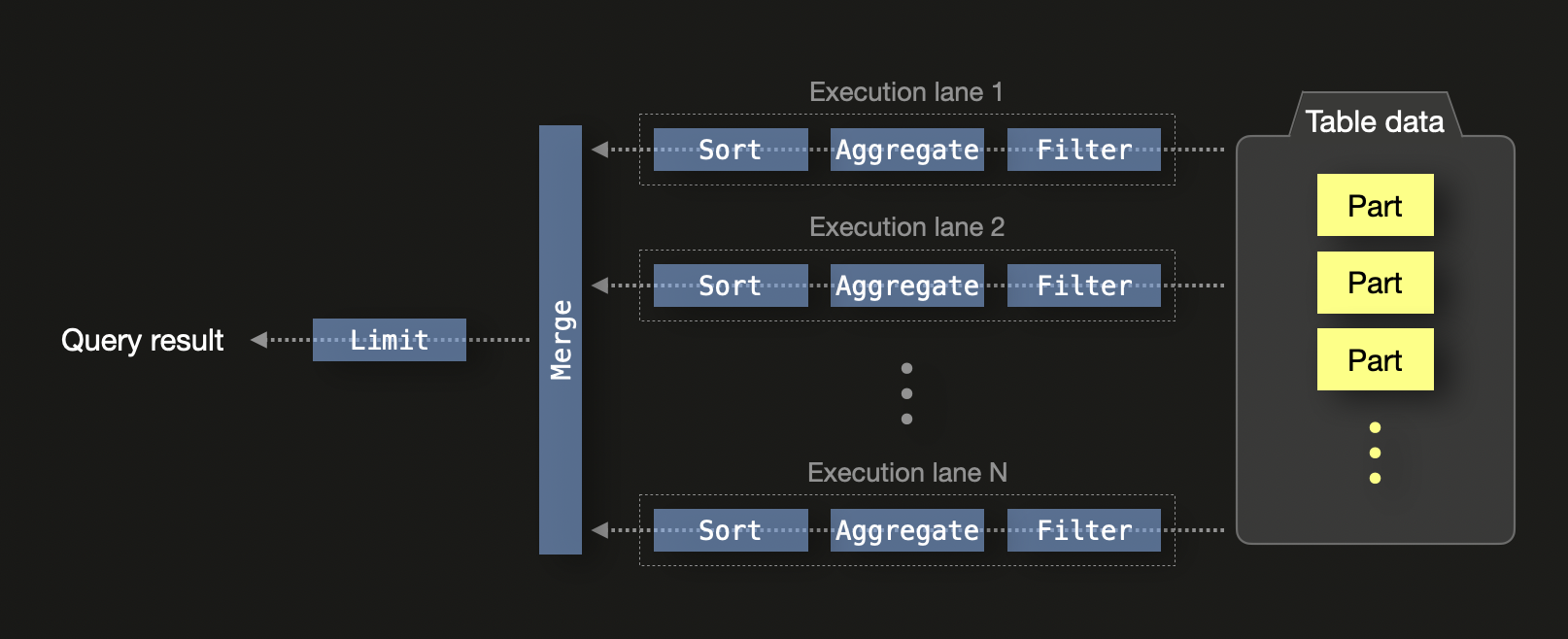
На едином узле канавки выполнения разбивают данные на независимые диапазоны, позволяя параллельную обработку через потоки ЦП. Это включает фильтрацию, агрегацию и сортировку. Локальные результаты из каждой канавки в конечном итоге объединяются, и оператор ограничения применяется, в случае если запрос включает условие ограничения.
Выполнение запросов дополнительно параллелизуется:
- Векторизация SIMD: операции над столбцовыми данными используют инструкции SIMD для CPU (например, AVX512), позволяя пакетную обработку значений.
- Параллелизм на уровне кластера: в распределенных настройках каждый узел выполняет обработку запроса локально. Частичные состояния агрегации передаются на инициирующий узел и объединяются. Если ключи
GROUP BYсоответствуют ключам шардирования, может быть уменьшено или полностью избегнуто объединение.
Эта модель позволяет эффективно масштабироваться на ядрах и узлах, делая ClickHouse хорошо подходящим для аналитики в большом масштабе. Использование частичных состояний агрегации позволяет объединять промежуточные результаты из различных потоков и узлов без потери точности.
Elasticsearch, напротив, назначает один поток на шард для большинства агрегаций, независимо от того, сколько ядер ЦП доступно. Эти потоки возвращают результаты локальных шарда топ-N, которые затем объединяются на координационном узле. Этот подход может недостаточно использовать системные ресурсы и вводить потенциальные неточности в глобальные агрегации, особенно когда частые термины распределены по нескольким шардом. Точность можно улучшить, увеличив параметр shard_size, но это происходит за счет увеличенного использования памяти и задержки запроса.
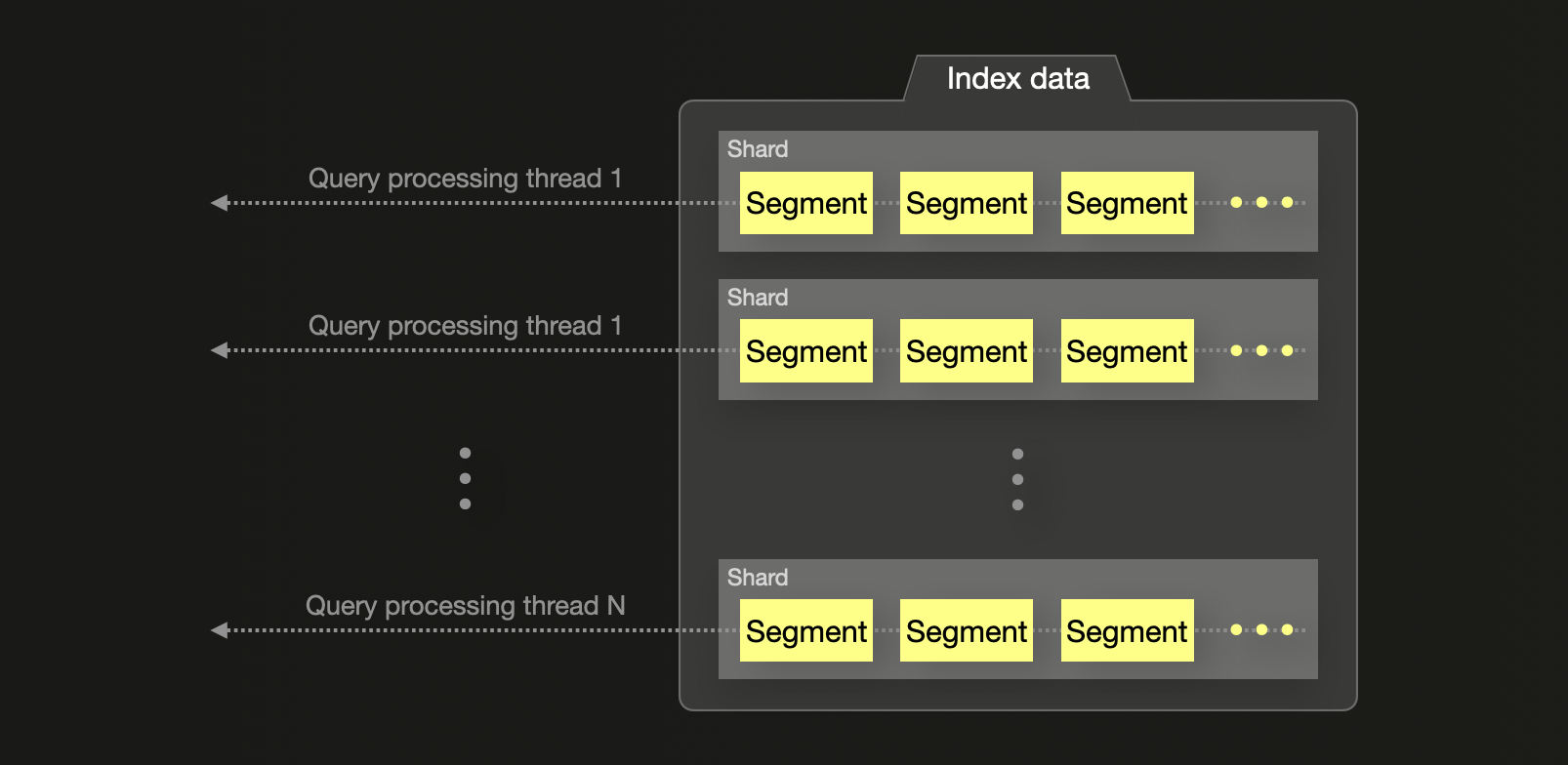
В заключение, ClickHouse выполняет агрегации и запросы с более высоким уровнем параллелизма и большим контролем над аппаратными ресурсами, в то время как Elasticsearch полагается на выполнение на уровне шардов с более жесткими ограничениями.
Для дальнейших деталей о механике агрегаций в соответствующих технологиях мы рекомендуем блог-пост "ClickHouse против Elasticsearch: Механика агрегаций по счету".
Управление данными
Elasticsearch и ClickHouse применяют принципиально разные подходы к управлению данными наблюдаемости временных рядов — особенно в отношении хранения данных, ротации и уровней хранения.
Управление жизненным циклом индекса против нативного TTL
В Elasticsearch управление данными на длительный срок осуществляется через Управление жизненным циклом индекса (ILM) и Потоки данных. Эти функции позволяют пользователям определять политики, которые регулируют, когда индексы ротации (например, после достижения определенного размера или возраста), когда старые индексы перемещаются в более низкозатратное хранилище (например, теплый или холодный уровни), и когда они в конечном итоге удаляются. Это необходимо, потому что Elasticsearch не поддерживает ротацию шардов, и шард не может расти бесконечно без деградации производительности. Для управления размерами шардов и поддержания эффективного удаления новые индексы должны периодически создаваться, а старые удаляться — эффективно вращая данные на уровне индекса.
ClickHouse применяет другой подход. Данные обычно хранятся в единой таблице и управляются с помощью TTL (время жизни) выражений на уровне столбца или партиции. Данные могут быть партиционированы по дате, что позволяет эффективно удалять их без необходимости создания новых таблиц или выполнения ротации индексов. Когда данные стареют и соответствуют условию TTL, ClickHouse автоматически удалит их — не требуется дополнительная инфраструктура для управления ротацией.
Уровни хранения и архитектуры горячее-теплое
Elasticsearch поддерживает горячие-теплые-холодные-замороженные архитектуры хранения, где данные перемещаются между уровнями хранения с разными характеристиками производительности. Это обычно настраивается через ILM и связано с ролями узлов в кластере.
ClickHouse поддерживает уровневое хранение через родные движки таблиц, такие как MergeTree, которые могут автоматически перемещать старые данные между различными объемами (например, SSD к HDD к объектному хранилищу) на основе кастомных правил. Это может имитировать горячий-теплый-холодный подход Elastic — но без сложности управления несколькими ролями узлов или кластерами.
В ClickHouse Cloud это становится еще более плавным: все данные хранятся в объектном хранилище (например, S3), а вычисления отделены. Данные могут оставаться в объектном хранилище до запроса, в котором они извлекаются и кешируются локально (или в распределенном кеше) — предлагая тот же ценовой профиль, что и замороженный уровень Elastic, с лучшими характеристиками производительности. Этот подход означает, что данные не нужно перемещать между уровнями хранения, делая горячие-теплые архитектуры избыточными.
Rollups и инкрементные агрегаты
В Elasticsearch rollups или агрегаты достигаются с помощью механизма, называемого трансформациями. Они используются для суммирования данных временных рядов с фиксированными интервалами (например, почасовым или суточным) с использованием модели скользящего окна. Эти трансформации настраиваются как периодические фоновые задания, которые агрегируют данные из одного индекса и записывают результаты в отдельный индекс rollup. Это помогает снизить стоимость дальностных запросов, избегая повторных сканирований сырых данных с высокой кардинальностью.
Следующая диаграмма схематически демонстрирует, как работают трансформации (обратите внимание, что мы используем синий цвет для всех документов, принадлежащих одной корзине, для которой мы хотим предварительно рассчитать агрегированные значения):
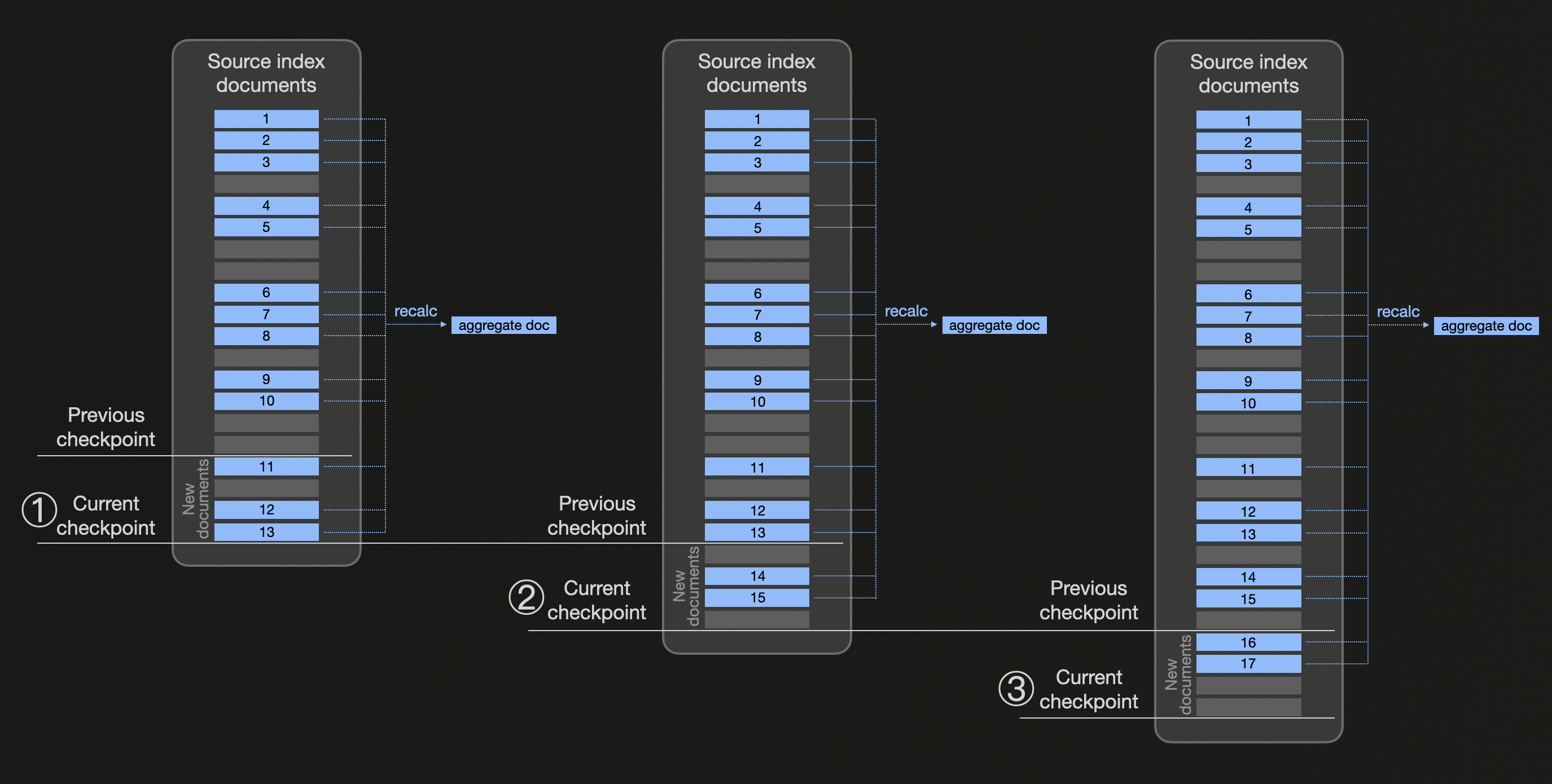
Непрерывные трансформации используют точки контроля на основе настраиваемого интервала проверки времени (частота трансформации frequency со значением по умолчанию 1 минута). На диаграмме выше мы предполагаем, что ① новая точка контроля создается после истечения времени интервала проверки. Теперь Elasticsearch проверяет изменения в исходном индексе трансформаций и обнаруживает три новых blue документа (11, 12 и 13), которые существуют с момента последней точки контроля. Поэтому исходный индекс фильтруется по всем существующим blue документам, и с помощью композитной агрегации (для использования пагинации результатов) агрегированные значения пересчитываются (и целевой индекс обновляется документом, заменяющим документ, содержащий предыдущие значения агрегации). Аналогично, на ② и ③ новые точки контроля обрабатываются путем проверки на изменения и пересчета агрегированных значений для всех существующих документов, принадлежащих одной и той же 'blue' корзине.
ClickHouse использует совершенно другой подход. Вместо того чтобы периодически переагрегировать данные, ClickHouse поддерживает инкрементные материализованные представления, которые преобразуют и агрегируют данные во время вставки. Когда новые данные записываются в исходную таблицу, материализованное представление выполняет предопределённый SQL-запрос агрегации только на новых вставленных блоках, и записывает агрегированные результаты в целевую таблицу.
Эта модель стала возможной благодаря поддержке ClickHouse частичных состояний агрегации — промежуточных представлений агрегатных функций, которые могут храниться и позже объединяться. Это позволяет пользователям поддерживать частично агрегированные результаты, которые быстро запрашиваются и дешево обновляются. Поскольку агрегация происходит по мере поступления данных, нет необходимости запускать дорогие периодические задания или повторно суммировать более старые данные.
Мы схематически демонстрируем механику инкрементных материализованных представлений (обратите внимание, что мы используем синий цвет для всех строк, принадлежащих одной группе, для которой мы хотим предварительно рассчитать агрегированные значения):
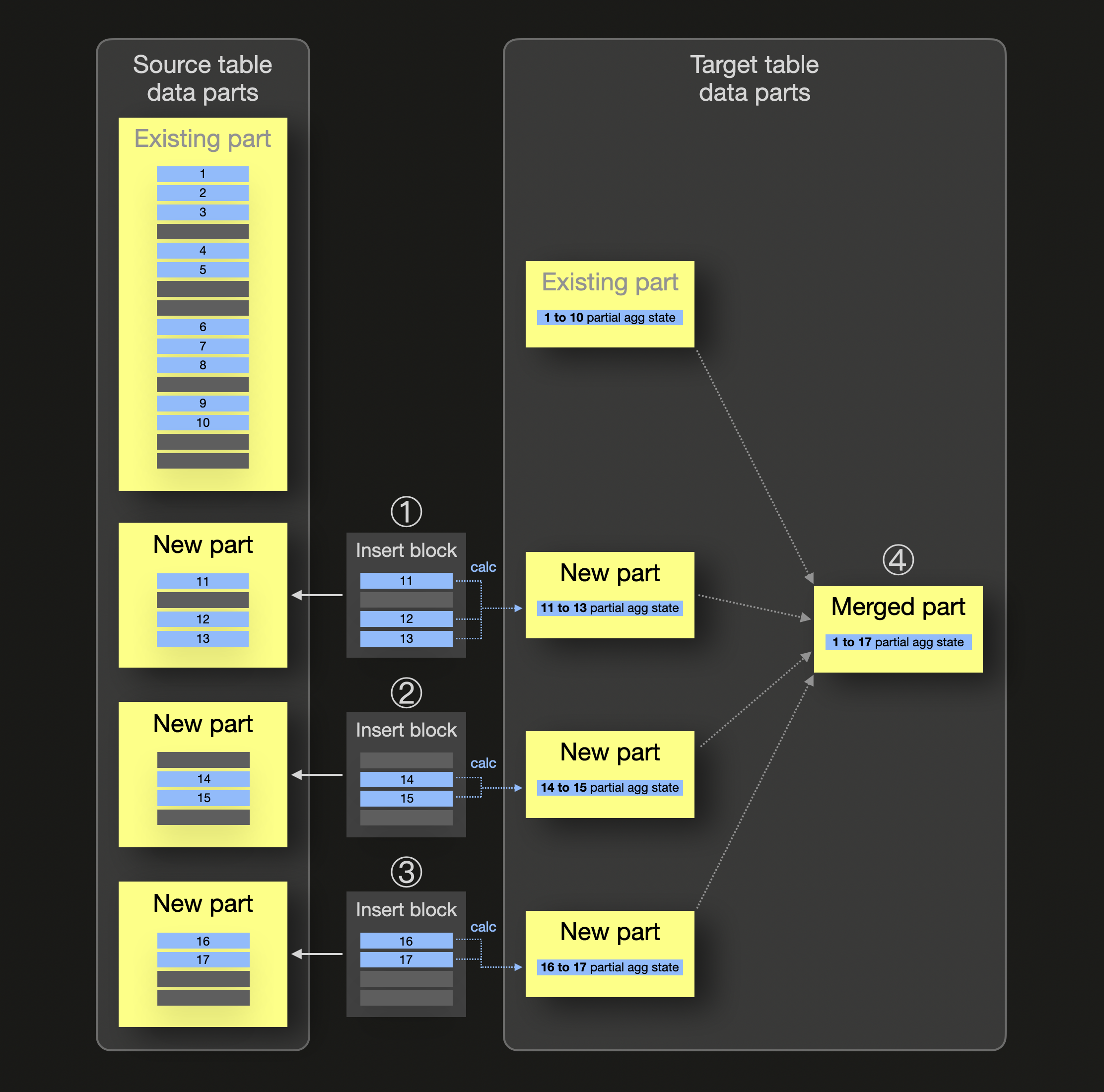
На диаграмме выше исходная таблица материализованного представления уже содержит часть данных, хранящую некоторые blue строки (с 1 по 10), принадлежащие одной и той же группе. Для этой группы также уже существует часть данных в целевой таблице представления, хранящая частичное состояние агрегации для группы blue. Когда ① ② ③ происходят вставки в исходную таблицу с новыми строками, создается соответствующая часть данных исходной таблицы для каждой вставки, и параллельно (только) для каждого блока вновь вставленных строк вычисляется частичное состояние агрегации и вставляется в виде части данных в целевую таблицу материализованного представления. ④ Во время фонового слияния частей частичные состояния агрегации объединяются, что приводит к инкрементной агрегации данных.
Обратите внимание, что все агрегатные функции (более 90 из них), включая их комбинации с комбинаторами функций агрегации, поддерживают частичные состояния агрегации.
Для более конкретного примера сравнения Elasticsearch и ClickHouse по инкрементным агрегатам смотрите этот пример.
Преимущества подхода ClickHouse включают:
- Всегда актуальные агрегаты: материализованные представления всегда синхронизированы с исходной таблицей.
- Без фоновых заданий: агрегации выполняются во время вставки, а не во время запроса.
- Лучшая производительность в реальном времени: идеально подходит для нагрузок по наблюдаемости и аналитики в реальном времени, когда свежие агрегаты нужны мгновенно.
- Составляемость: материализованные представления могут комбинироваться или объединяться с другими представлениями и таблицами для более сложных стратегий ускорения запросов.
- Различные TTL: для исходной таблицы и целевой таблицы материализованного представления могут применяться разные настройки TTL.
Эта модель особенно мощная для сценариев наблюдаемости, когда пользователям необходимо вычислять метрики, такие как ошибки в минуту, задержки или разбивки по топ-N, без сканирования миллиардов сырых записей для каждого запроса.
Поддержка Lakehouse
ClickHouse и Elasticsearch используют принципиально разные подходы к интеграции с lakehouse. ClickHouse является полноценным движком выполнения запросов, способным выполнять запросы над форматами lakehouse, такими как Iceberg и Delta Lake, а также интегрироваться с каталогами дата-озер, такими как AWS Glue и Unity catalog. Эти форматы рассчитывают на эффективное выполнение запросов по файлам Parquet, которые ClickHouse полностью поддерживает. ClickHouse может непосредственно читать как таблицы Iceberg, так и таблицы Delta Lake, что позволяет бесшовно интегрироваться с современными архитектурами дата-озер.
В отличие от этого, Elasticsearch тесно связан со своим внутренним форматом данных и хранилищем на основе Lucene. Он не может напрямую запрашивать форматы lakehouse или файлы Parquet, что ограничивает его способность участвовать в современных архитектурах дата-озер. Elasticsearch требует, чтобы данные были преобразованы и загружены в его проприетарный формат, прежде чем они смогут быть запрошены.
Возможности ClickHouse в области lakehouse выходят за рамки простой загрузки данных:
- Интеграция с каталогами данных: ClickHouse поддерживает интеграцию с каталогами данных, такими как AWS Glue, что позволяет автоматически обнаруживать и получать доступ к таблицам в объектном хранилище.
- Поддержка объектного хранилища: нативная поддержка запросов к данным, находящимся в S3, GCS и Azure Blob Storage без необходимости перемещения данных.
- Федерация запросов: возможность коррелировать данные из нескольких источников, включая таблицы lakehouse, традиционные базы данных и таблицы ClickHouse, с использованием внешних словарей и табличных функций.
- Инкрементная загрузка: поддержка непрерывной загрузки из таблиц lakehouse в локальные MergeTree таблицы с использованием таких функций как S3Queue и ClickPipes.
- Оптимизация производительности: распределенное выполнение запросов по данным lakehouse с использованием кластерных функций для повышения производительности.
Эти возможности делают ClickHouse естественным выбором для организаций, которые внедряют архитектуры lakehouse, позволяя им использовать как гибкость дата-озер, так и производительность столбцовой базы данных.
